システム奮闘記:その31
Linux,Windowsのファイルシステム入門
(2004年5月19日に掲載)
はじめに
ファイルシステムと言っても、どんな役目をするのか、あまり見えてこない。
それどころか、何も知らなくても問題なかったので、手を出さなかった。
しかし、ある事をキッカケに、ある程度は知る必要があると感じました。
そこで「ファイルシステムって何?」について書いてみる事にしました。
副題は「事務員でもわかるファイルシステム入門」の巻。
ファイルシステムとの出会い
Linuxを導入した時、kernel-2.2系だったので、選択肢は、ext2しかなかった。
そのため、何も考えずに、ext2を使っていた。
もちろん、ファイルシステムの役目なんぞ知る由もなかった (^^;;
2001年12月のある日、ファイルシステムの役目を知るキッカケができた。
ある部長に「うちの家のパソコンが、どうもうまく動かへんから、
見に来てくれへんか?」と言われた。
そこで部長の家へ行くことにした。
パソコンを見ると、ソフトを削除する際、「アプリケーションの追加と削除」を
選ばずに、誤ってフォルダ─ごと削除したため、動作に不具合が生じていた。
私は「これは、OSの再インストールしかないなぁ」と思った。
部長の家族の方から「容量が不足しやすいのです」という話を聞いた。
ハードディスクの容量は3Gだが、ディスクパーティションを見ると、
2Gと1Gに分割していた。
そこで私は「3Gをまとめてしまえば、問題は解決できるなぁ。
そのためには、やはりOSの再インストールしかないなぁ」と思った。
ちなみに、OSは、Windows98だった。
Windows98の再インストールは簡単にできる。
そこで、作業開始になった。ファイルシステムの選択が出てきた。
FAT16とFAT32だった。
再インストールの説明書にはFAT16と書かれていたので、
FAT16でインストールをした。すると・・・
なんで、2Gしか認識してくれへんねん (TT)
だった。つまり2Gと1Gにディスクが別れる現象が起こった。
何度やっても同じだった。
そこで、Windowsの説明書を読むと、FAT16だと2GBしか認識できないが、
FAT32だと2TBまで認識できる事がわかった。この時・・・
ファイルシステムに、そんな違いがあったのか!!
と初めて知った。
ここで1つ学習。
ファイルシステムの設計の違いで認識できるディスク容量に違いが出る。
この日、部長の家で晩飯を、ごちそうになり、その上、バイト料まで頂いた (^^)
Windowsのファイルシステム。FAT16、FAT32とNTFS
部長の家での学習をキッカケに、ファイルシステムの勉強をするかと思えば、
全くしなかった。1年数ヵ月ほど冬眠に入った。
そして、2003年3月に、また、勉強するキッカケが出てきた。
それは、会社でWindows2000Proをインストールする事になったからだった。
ファイルシステムの選択で、FAT32と、NTFSがあった。
そこで、私は、自分が知っているFAT32を入れてみた。
Windows2000Proの場合、UNIX系のOS同様、ファイルに所有者が設けられ
アクセス制限などの設定ができる。
早速、自分の目で確かめる事にしたのだが・・・
一般ユーザーでも、管理者権限のファイルが自由にのぞける!
この事実を目の当たりにした時
なんでやねん!
と思った。
そこで、試しに、NTFSで再インストールすると、うまくいった。
この時、わかった事は・・・
FAT32だと、アクセス制限ができないが
NTFSだとUNIXのようなアクセス制限の制御ができる!
この時は経験則として上のような認識を持ったが、2003年9月に
ファイルシステムについてを少し調べる事になった。
ファイルシステムのアクセス制御に関して「パソコン技術体系2002 OS編」に
明確な答えが書かれていた。
| FATとNTFSの違い |
|---|
| FAT |
FATには、ファイルの所有者やアクセス権を記録させる部分がない。
そのため、Windows2000Proであっても、FAT32を使えば
管理者(アドミン)のファイルを、一般のユーザーが自由に
見る事が可能になる。
|
| NTFS |
NTFSには、UNIX系のファイルシステム同様、ファイルの所有者や
アクセス権を記録させる事ができるため、機密保持ができる。
|
ちなみに、「NTFS」の意味。
「New Technology File Systems」から由来している。
面倒くさいので調べる気は起こらないが、WindowsNTは、New Technologyから
由来しているかもしれないので、そのまま引用しているのかもしれない。
だが、次の突っ込みをマイクロソフトに対してしたくなった。
| マイクロソフトに対してしたくなった突っ込み |
|---|
Sよ、おめぇーはXENIXというUNIXを売ってたやろ!
アクセス制御をしているファイルシステムぐらい入れていたやろ!
単なる技術転用やろ! どこが新しい技術のファイルシステムやねん!
|
だが、ファイルシステムの違いによって、ファイルへのアクセス制限の機能の有無は
私にとって大きな発見だった。
実は、2000年に同僚が次の要望がしていたからだった。
社内のWindows98にパスワードを設けられないか
だった。
当時、Windows98のコントロールパネルを開いて、パスワードを設定したが、
パスワード無しでもログインできる。もちろん、他人のファイルは簡単にみられる。
パスワードの意味がない。当時、「わけがわからんなぁ」と思いながら、
会社には「できない」と回答した。
しかし、この発見で、他人のファイルが丸見えなどの理由がわかった。
要するに、ファイルシステムにファイルの所有者を記録させたり、
アクセス制限を記録する部分がないためだった。
3年かけて辿り着いたが、謎が解けて良かったと思った (^^)V
もし、同じ問い合わせが来ても、単に「できない」だけでなく
キチンと理由を説明できるので、納得してもらえる。
ファイルシステムの重要性を知る
しかし、この時は、ファイルシステムの話の重要性を認識していなかったため、
勉強する動機も起こらず、再び冬眠に入った。
だが、半年たった2003年11月に、また目覚める事になった。
2003年11月21日、BLUEのMLでファイルシステムの事が話題になった。
もちろん、内容についていけない私は、流し読みする程度だったが、
後藤さんが投稿された記事が目に入ったからだった。
| 私がファイルシステムに目覚めるキッカケになった内容 |
|---|
ところで、ext2 の実装がここに書かれている通りだとすると、ファイルシステム
に対しての書き込み中に何かが起きた場合には、データが保全できるかどうかは
運次第であり、ext3 でもあまり安心できないということになります。ふ〜む…
また、ext3, ReiserFS, Linux-JFS は、ベースとなる Linux の VFS の書き込み
順序が間違っているために XFS に比べて破損確率が高く、残念ながら XFS でも
完璧とは言えないとなっています。
|
これを読んだ私は次のような事を感じた。
不具合により、データがパアになる危険性が・・・
「もし、社内のサーバーのファイルシステムの不具合で、データがダメになったら
とても対処なんぞできるわけがない」と思った。
かなり危機感を感じた私は、危機管理をキチンとしようと考えたため、
ファイルシステムについて勉強せねば・・・
と思った。
でも、ファイルシステムに関して、わかりやすい本なんぞない。
もし、「ファイルシステム入門」というタイトルの本が出ていれば、
冬眠なんぞせずに勉強しているのだ。
そこで、良い本を紹介してもらおうと考え、BLUEのMLに次のメールを投稿した。
| 私が投稿した内容 |
|---|
菅@Linux好き事務員です。
こんにちは。
> ところで、ext2 の実装がここに書かれている通りだとすると、ファイルシステム
> に対しての書き込み中に何かが起きた場合には、データが保全できるかどうかは
> 運次第であり、ext3 でもあまり安心できないということになります。ふ〜む…
>
> また、ext3, ReiserFS, Linux-JFS は、ベースとなる Linux の VFS の書き込み
> 順序が間違っているために XFS に比べて破損確率が高く、残念ながら XFS でも
> 完璧とは言えないとなっています。
ファイルシステム関連のメールをやりとりを拝見していまして、
ファイルシステムの選択などが大事なのかと思いました。
「FATが腐っている」などを見ますと、「???」という状態でした (^^;;
もし、どなたか、誰でもわかりそうなファイルシステム関連の本を
ご存知でしたら、紹介して頂けませんでしょうか。
よろしくお願いいたします m(--)m
|
投稿すると、後藤さんから、お返事をいただいた。
| 後藤さんからのお返事 (一部抜粋) |
|---|
> 「FATが腐っている」などを見ますと、「???」という状態でした (^^;;
「FAT は根本的に腐っていて、ダメダメなものだ」というのは、MS-DOS
時代からコンピュータを使っている者にとっては「常識」のひとつです。
FAT は元々、1980年代前半の(今と比べれば)貧弱なハードウェアリソースを
使い、320KB 〜 1MB 程度のフロッピーディスクを管理するものとして
実装されているためか、良く言えば簡素、悪く言えば手抜きな設計と
なっています。
詳細を書いていると長くなるので省きますが、大きな問題点としては
みっつほどあります。
ひとつは、FAT のクラスタチェインを用いる管理方式が障害に極めて
弱いこと。ふたつめは元々フロッピーを前提に考えられたシステムで
あるため、大容量ディスクの取扱いに難があること(FAT12 -> FAT16
-> FAT32 とあがいては来たが、もうボロボロ)、そしてみっつめは
セキュリティ機構が何も働かないことです。
う〜ん… 例えば NTFS について知りたければ、アスキーから出版された
「Inside Windows NT ファイルシステム」 ISBN4-7561-0302-2 とか、
O'REILLY の「Windows NT ファイルシステム詳説」ISBN4-900900-70-2
などがありますが…
「ファイルシステムというものについて」の入門書みたいなものって
あったかなぁ…
UFS にしろ、ext2 にしろ何にしろ、実装の問題になるのでカーネル
解説書の類いじゃないと、ないような。
|
後藤さんの「FATが腐っている」という意味の3つ目が納得できた。
セキュリティー機能がボロボロだという意味だ。
確かに、ファイルにアクセス制御がかけらないのは事実だ。
だが、この時は残り2つの事が理解できなかった。
| この時、理解できなかった2点 |
|---|
| (1) |
クラスタチェインを用いる管理方式が障害に極めて弱いこと |
| (2) |
大容量ディスクの取扱いに難があること |
当時、理解できるまでの知識がなかったからだった。
この2点の問題については、後述しています。
小山さんからも本の紹介を頂きました。
| 小山さんからのお返事 |
|---|
数少ないファイルシステムを解説した本として、Linux 関係の本ではないの
ですが
BeOS:ファイルシステム - 実践ファイルシステム構築
ドミニク・ジャンパオロ著
糸魚川 茂夫訳
http://www.amazon.co.jp/exec/obidos/ASIN/4274078876/
という書籍があります。メインは BFS という BeOS のファイルシステムの解
説ですが、FAT, NTFS, HFS, ext2, XFS なども取り上げていて、ファイルシス
テムの基礎技術を俯瞰するにも適しています。
|
さて、後藤さんと小山さんから紹介してくださった本を探しに書店に行った。
だが、後藤さんの紹介のO'REILLY の「Windows NT ファイルシステム詳説」は
内容が難しい上、C言語の話が出ている
とても事務員では歯が立たない内容だった。
小山さんから紹介してくださった本を探したが、いくつかの書店を探したが
見つからなかった。
お二人のご好意に応えられないのが申し訳ない感じがした・・・。
冬眠から目覚めてファイルシステムの勉強開始
どこから攻めて良いのか、わからないし、どこまで知る必要があるかもわからない。
身動きが取れないため、また、冬眠(要するに先送り)する事になった (--;;
しかし、冬眠の間隔が短くなっているのか、今度は、2004年2月に覚めた。
雑誌「SoftDesign3月号」の記事がキッカケだった。
ファイルシステムについて触れられている。
少しでも理解できればと思い、早速、買ってみた。
そして、ファイルシステムの部分を読んでいく事にした。
ファイルシステムの役割が書かれていた。
| ファイルシステムの役割(要約) |
|---|
ディスク操作において、磁気へッドを、読み書きしたいトラックへ持っていく
時間(シーク時間)がネックになるため、いかに、シーク時間を少なくするのが
読み書きのスピードの度合いになってくる。
そのため、ファイルシステムは、ディスクのどこに何が格納されているのか管理し
どこが空き領域で、ファイル作成・拡張したい時、どの領域を割り当てるのか
を決定する役割がある。
また、ディスクの効率的利用以外にも、耐障害性もファイルシステムの役割だ。
|
「なるほどなぁ」と感心しながら、ファイルシステムの解説を読んでいた私だが
この時、わかった気になっただけで、実際には、あまり理解していなかったのだ (^^;;
| ブロックの構造 |
|---|
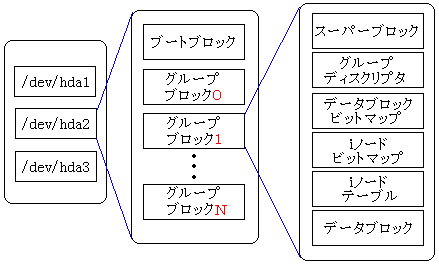 |
|
一般的に、よく見られるext2のブロック構造の図です。
|
ブロック図の説明を見ていくと、ディスクの使用状況を管理するため、
ビットマップを利用すると書かれている。
各ブロックごとに、1ビットを割り当てた配列で、使用中を「1」で、
未使用を「0」にして使用状況を表すという。
ところで、iノードテーブルや、データブロックは、同じグループ内に複数個、
存在するのだが、上の図を見ていると、1個だけのように思ってしまう。
そのため、次のような解釈をしてしまった
| 私が誤解した内容 |
|---|
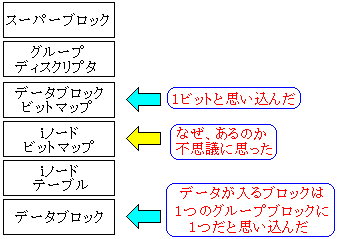 |
スーパーブロック、グループディスクリプタなどの管理データを保管する部分は
データブロックと同じサイズのブロックとは思わなかった (^^;
雑誌には、ブロックサイズは1K、2K、4Kのどれかを選択されていると
書かれているのだが、この時、私はデータブロックの事だと思い込んでしまった。
この時、1つのグループに、1つのデータブロックしかないと思い込んだため
ブロックグループは大量にあると思ってしまった。
|
このような誤解をしてしまったため、後で、混乱するハメになった (--;;
(詳しくは後述しています)
雑誌には、スーパーブロックなどのファイル管理の情報が入っているデータを
「メタデータ」と言うと書かれていた。
メタデータが破壊されると、実際のデータは無事でも、どこにデータがあるのか
わからなくなるため、データが消えたようになるという。
そこで、fsckコマンドは、メタデータの整合性をチェックするためにあるという。
この時、fcskコマンドの意味を、ほとんど理解はできなかったのだが、
メタデータの重要性と、メタデータの修復に、fcskコマンドが使われることが
なんとなく、わかった。
ここまでの発見
ファイルシステムの事について、調べていると、意外な発見があった。
それは・・・
/procディレクトリーの存在
だった。
このディレクトリーは、プロセスファイルシステムと呼ばれる部分で、
実行中のメモリーの状態をファイルであるかの如く、見せかける働きをする。
もちろん、電源が切れたら、中のファイルは全て初期化される。
ブート時の設定ファイルの命令の影響で、実行中のメモリーの中身が変わるため、
このディレクトリーの中身も書き変わる仕組みになる。
この話を知って、以前から持っていた謎が1つ解けた!
「システム奮闘記:その21」でも取り上げましたが、iptablesを使う時、
パケットの転送が可能になるように、次のコマンドを打つ必要がある。
echo "1" >/proc/sys/net/ipv4/ip_forward
これは、/proc/sys/net/ipv4/ip_forwardの中身を「1」に変更する命令なのだが、
パソコンの電源を切れば、勝手に初期値の「0」に戻ってしまう。
そのため、起動時に「1」にする方法として/etc/sysctl.confの中の記述を
net.ipv4.ip_forward = 1に変更する必要がある。
/proc/sys/net/ipv4/ip_forwardのファイルを書き換えているのに、
なんで、電源を切ったら、中身が初期化されるのか、私にとって、謎だった。
しかし、今回のように、実行中のメモリーの状態を、人間の目で見える
ファイルとして見せているため、元々、実体のないファイルを書き換えても、
パソコンの電源を切ってしまえば、元に戻るのは当然の話だ。
そのため、/etc/sysctl.confの記述をnet.ipv4.ip_forward = 1に変更する必要がある。
メモリーの状態を、人間の目で見える形にした、実体のないファイル。
このディレクトリーを調べると面白い事がわかってくる。
最大ファイル数、最大iノード数などの、稼働中のメモリーの情報が
一目でわかるようになっている。もちろん、変更な部分もある。
/procディレクトリーを触ってチューニングする話もあるが、今回は割愛します。
もし、「手を抜くな!」という声がありましたら、堂々と反論します。
そんな難しい事は、事務員の私には、すぐには理解できません (^^)V
/procディレクトリと/etc/sysctl.confに関する補足
(2009/4/19) |
|---|
/procディレクトリは、正確に書きますと、Linuxカーネルが
起動している際、メモリ上にあるカーネルの情報を
ファイルという形で可視化した物を表示するためのディレクトリなのだ。
そのため、いくら/procディレクトリの中身を変更しても
メモリ上の情報なので、Linuxを終了させると消滅してしまいます。
/etc/sysctl.confですが、カーネルパラメータを記述するファイルで
/procディレクトリのファイル(メモリ上のカーネルの情報)を
書き換えに使うファイルです。
これはカーネル起動後、起動スクリプトが動き出す段階で取り込まれ
メモリ上のカーネルの情報を書き換えます。
詳しくは「システム奮闘記:その76」をご覧ください。
(Linuxの起動スクリプト /etc/rc /etc/rc.sysinit /etc/inittabの解読)
|
ファイルシステムのクラスタ、セクタ
さてさて、わかったような、わからないファイルシステム。
しかも、その時は気が付いていなかったが、ext2のブロックの構造について、
誤解したまま前に進んでいる状態だった。
この壁を突き崩すのは難しい。
ふとした事で、ファイルシステムについて、Windowsに目を向けてみた。
いきなり「クラスタ」という文字が出てきた。
クラスタって何?
だった (^^;;
ext2では、データの記録する部分をブロックと読んでいるが、
WindowsのFATでは、クラスタと呼んでいる事を知った。
クラスタとは、いくつかのセクタをまとめた単位だという。
セクタって何?
だった (^^;;
セクタといえば、ハードディスクに関連する用語だというのは知っていた。
なぜなら、基本情報技術者(旧・情報処理2種)の試験は受けた事があり、
一応、勉強した経験があるからです。
しかし、こんな感じで、無知ぶりを披露している私なので、もちろん結果は・・・
見事に撃沈しました (--;;
だった (^^;;
久しぶりに、基本情報技術者の参考書を開いてみた。
セクタなどの説明が書かれていた。
| ハードディスクの円盤構造 |
|---|
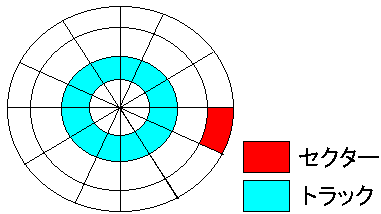 |
ハードディスクは円盤になっている。円周上の区域をトラックと呼び、
トラックを、いくつか分割した単位をセクタという。
セクタはハードディスクにデータを保存する際の、最小単位であり、
どんなに小さなファイルを書き込んでも、そのファイルのためだけに
1セクタを消費してしまう。2つ以上のファイルが1セクタに入る事はないため。
(注意)
上の文章を見て、おかしいと思った方がいるかと思います。
確かにおかしいです。それについては後述しています。
ちなみに、1セクタの大きさは、512バイトだったり、1024だったりする。
記憶装置によって、セクタの大きさが違うため、一概に「これだ」が言えない。
だが、実際のディスクの無駄な浪費は、そんな小さい物ではない。
詳しくは後述しています。
|
教科書を見ながら、今更ながら「へぇ〜」と思った。
Windowsのファイルシステムに話を戻して、調べていくと、
1クラスタ辺りの大きさが載っていた。
| 1クラスタ(1ブロック)辺りの大きさ |
|---|
| Linux ext2 |
1K、2K、4Kバイト (選択可) |
| FAT16 |
32Kバイト |
| FAT32 |
4Kバイト |
(注意)
FATの場合、パーティションの大きさで
クラスタの大きさが変わるぞという突っ込みがあるかと思います。
それに関しては後述しています。
|
さて、クラスタ(ブロック)は、データを保存するための最小単位の箱だ。
そのため、いくら小さなファイルを用意しても、1クラスタには、1つのファイルしか
書き込む事ができないため、残りの部分に無駄が生じる。
| クラスタサイズの違いによるディスクの無駄 |
|---|
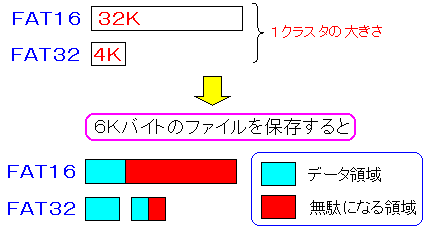 |
クラスタの大きさの違いによって、どれくらいディスクが無駄になるのか
簡単に計算してみた。
仮にディスクの中に1000個ファイルがあったと仮定する。
データの最後の部分を保存しているクラスタ部分に無駄が発生する。
ファイルの大きさはマチマチなので、平均すると、1クラスタの大きさの半分が
無駄な領域と考えられる。
そこで計算してみると・・・。
| クラスタの大きさによるディスクが無駄になる量 |
|---|
| ファイルシステム |
クラスタの大きさ |
無駄になる部分 |
| FAT16 |
32Kバイト |
16K×1000 ≒ 16M |
| FAT32 |
4Kバイト |
2K×1000 ≒ 2M |
この計算をして、自分の目を疑いたくなった。
FAT16の場合、たった1000個のファイルの保管のために、
16Mバイトも無駄にしているとは、普通の感覚では考えにくいからだ。
でも、こんな単純な計算を間違えするわけがない。
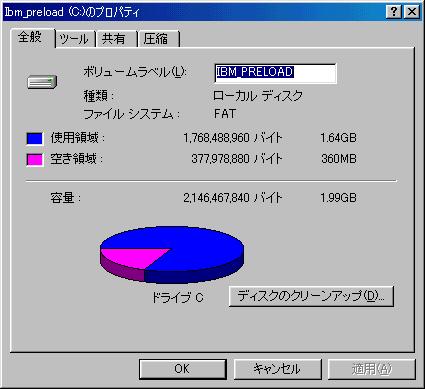
だが「論より証拠」で、2Gのディスク上で実験を行った。
元々、FAT16が入っている所に、FAT32への変換を行い、
どれくらいディスク容量に空きができるのか、実際に目で確かめる事にした。
| FAT16からFAT32へ変換した結果 |
|---|
| FAT16の場合 | FAT32へ変換した後 |
 |
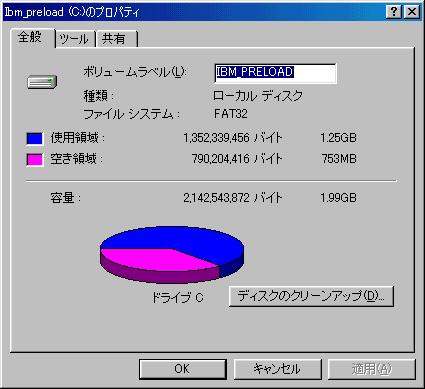 |
理論で考えても、納得しにくかったのだが、実際に、実験を行ってみて
400Mバイト近くも容量が増えたのには驚いた!!
|
なんてFAT16は無駄なファイルシステムだと思いながら、次のように思った。
クラスタサイズは小さければ、小さいほど良い!
確かに、ディスクの無駄がなくなる事は良い事だ。
しかし、その考えで進むと、別の問題が生じる事が、すぐ後でわかった。
それは、ディスクへのアクセス時間の問題だ。
ところで、ディスクアクセスの時間に関して調べていると、
FATは、パーティションサイズによって、クラスタのサイズが変わる事を知った。
|
パーティションの大きさによるクラスタのサイズの違い |
|---|
| ファイルシステム |
パーティションサイズ |
クラスタのサイズ |
| FAT16 |
256M〜512M |
8K |
| FAT16 |
512M〜1G |
16K |
| FAT16 |
1G〜2G |
32K |
| FAT32 |
512M〜4G |
16K |
| FAT32 |
4G〜8G |
4K |
| FAT32 |
8G〜16G |
8K |
| FAT32 |
16G〜32G |
16K |
| FAT32 |
32G以上 |
32K |
実は、これだけだはないのだが、面倒くさいので割愛します (^^;;
なぜ、こんな奇妙な事をするのか、理解しがたいものがあるのだが、
Microsoftのやる事だから、ありがちなパターンだと思う。
さて、話をディスクへのアクセス時間を戻して、なぜ、アクセス時間に
影響するのか調べてたら、次の事がわかった。
仮に100Kバイトのファイルがあるとする。
この場合、何クラスタができるかを考える必要がある。
|
100Kバイトのファイルは、何クラスタになるのか |
|---|
| ファイルシステム |
クラスタのサイズ |
クラスタ数 |
FAT16
(256M〜512M) |
8K |
13個 |
FAT16
(512M〜1G) |
16K |
7個 |
FAT16
(1G〜2G) |
32K |
4個 |
FAT32
(4G〜8G) |
4K |
25個 |
ここで言えるのは、クラスタのサイズが小さいほど、クラスタの数が多くなり
ディスクへ読み込む際、該当のクラスタへ接続する回数が増える事を意味する。
クラスタサイズが32Kだと、4回で済む所を、クラスタサイズが4Kの場合
25回も読み込む作業が出てくる。
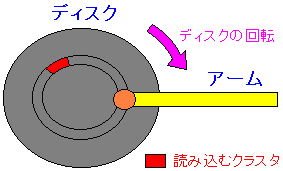
ディスクのデータを読み込む際、読み込むためのアームを、データが記録されている
ディスク円盤の該当トラックの位置にまでもっていく必要がある。
| アームの動き |
|---|
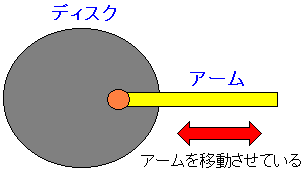 |
データが記録されているディスク円盤の該当トラックへアームを持っていて
トラック上の中の該当クラスタのデータを読み込んでいる。
アームを移動させるのには時間がかかる。その時間の事を「シーク時間」という。
|
同じトラック上に、該当のクラスタが全部あるとは限らない。
そのため、クラスタの数が多いと、アームの移動時間が大きく響く場合が出てくる。
特に、ディスクの断片化が起こっている時は、最悪だ。
| ディスクの断片化 |
|---|
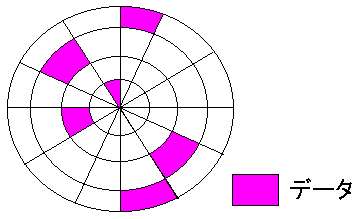 |
クラスタがディスク上でバラバラに存在している状態を「断片化」という。
これが起こる原因は、通常、ディスクの書き込む際、ディスク上の順番に
書き込むようだが、ファイルが削除された場合、そこに空きができる。
時間が経つにつれ、まとまった領域がなくなり、歯抜けの空きばかりになる。
その時に、データを書き込むと、歯抜けの空き状態の部分を埋めようとするので
自然と、ディスクの断片化が進んでしまう。
|
断片化していると、アームの移動に時間が取られる。
それだけでなく、アームを移動させた後、該当のクラスタが
アームの所にやってくる時間も考慮する必要が出てくる。
| 待ち時間について |
|---|
 |
アームを移動させた後、該当のクラスタがやってくるまでの時間を「待ち時間」という。
待ち時間は、アームが該当のトラックに到着した際に、該当クラスタが、どこにあるかで
待ち時間が変わってくる。そのため、個々のケースでの待ち時間は算出が困難。
そこで出てくるのが「平均待ち時間」だ。待ち時間を平均すると、アームが
該当トラックに到着してから、ディスク円盤が半回転するまでの時間になる。
例えば、1分間に5000回転するディスクの場合の「平均待ち時間」は
60÷5000÷2=0.006秒になる。6ミリ秒だ。
|
よく基本情報処理技術者の試験で、ディスクへのアクセス時間の問題が出てくる。
ディスクへのアクセス時間 = シーク時間 + 平均待ち時間 + データ転送時間
になっている。
ところで、データ転送時間とは何が問題になる。
ここでカッコ良く解説から入り、いかにも、わかっていた素振りを見せたいのだが
どうせバレるので、最初から正直に
私は、わかりませーん (^^)
と表明しまして、実際に、どうやって求めるのか教科書を調べる事にした。
データ転送量とは、目的のデータがアームの下を通過する際に、
そのデータを読み込む(書き込む)間の時間を意味する。
基本情報技術者の試験では、1ブロック(1クラスタ)あたりのデータを
読み込むのにかかる時間を求めなさいと出題される。
そこで、1ブロック(1クラスタ)を読み込む(書き込む)時間を
考えていくことにする。
まずは、データ転送速度を求める必要がある。
これは1秒間に、どれくらいのデータ量を読み込めるのかを表す。
データ転送速度 =1トラックのデータ量 × 1秒間のディスク回転数
もちろん、転送速度の単位は「バイト/秒」になる。
さて、1秒間に、どれくらいのデータを読み込める(書き込める)のか
わかった所で、1クラスタのデータを読み込むのに、どれくらいの時間がかかるのかを
求めれば良いので
データ転送時間 = 1クラスタのデータ量 ÷ データ転送速度
という感じで、データ転送時間が求められる。
ふぅ、これで基本情報処理技術者の問題の解答方法を習得した (^^)
でも、1問を解くために、ここまでの労力がかかってしまうので、
いかに「基本情報技術者」の試験を通過するのが困難かがわかる。
これを見る限り、クラスタのサイズが小さい場合は、ディスクアクセス時間が
問題になってくるのがわかる。
小さいファイルなら、まだしも、大きなファイルを読み込んだりする場合、
ディスクの断片化がされていると、時間がかかるのが、わかる。
ところで、Windowsの機能としてお馴染の「デグラグ」がある。
断片化されたディスクのクラスタを整頓するための作業だ。
実は、今まで、デフラグの作業は、ほとんどした事がなかった。
ディスクアクセスが遅くなったのを体感していなかったのがあるからだ。
(例え、遅くなっても、その辺りは無頓着な所もあるため)
しかし、調べていくと、ディスクアクセス時間や、起動時間が遅くなるだけでなく
ファイルの破損や、システムが固まるのを引き起こす原因につながるという。
この話を知った時、次のように思った。
デフラグは大事な作業だった (--;;
善は急げで、早速、自宅と会社のパソコンのデフラグを行なった。
肝心のLinuxサーバーは、どうしようと思い、デフラグツールを探したら、
なかなか見つからない。
「ブロックサイズが1K〜4Kだから、断片化すると大変なのに」と思いつつ、
調べていくと、意外な結果がわかった。
Linuxのファイルシステムは断片化が起こりにくい!
ext2、ext3の場合、ディスクの書き込みをする際、隣の8ブロックを予約として
確保する仕組みになっている。「先行割り当て」と呼ばれる機能で、
そうする事により、データをなるべく近くに置いてシーク時間を短縮する狙いがある。
WindowsNT系のファイルシステム「NTFS」は断片化が起こりにくい設計と
Microsoftは言っているようだが、実際には、断片化が起こっているし、
デフラグ機能や、Microsoft以外からも、デフラグのためのソフトが出ている。
「起こらない」ではなく「起こりにくい」なので、詐欺とは言えないが、
それにしても「なんだかなぁ」と思ってしまう。この話を知った時、改めて
Linuxのファイルシステムは素晴らしい!
と感激してしまう (^^)
さて、調べている間に、ディスク円盤は一つでない事を知った。
何枚も円盤が重なっている。
| ディスク構造について |
|---|
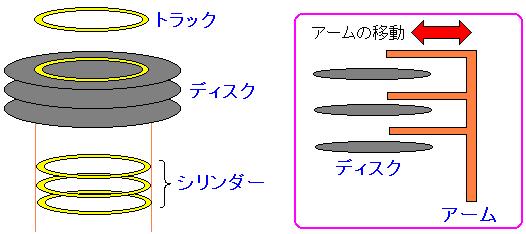 |
ディスク円盤は、1枚だけでなく複数枚、存在する。
さて、アームを動かさなくて良い部分の集合体の事をシリンダという。
つまり、同じトラックの集合体の事を意味する。
シリンダ(Cylinder)の本来の意味は、円筒という意味で
同じトラックの集合体が円筒形になる事から「シリンダ」と呼ばれる。
|
どんどん知らない事が沸いて出てくるなぁと思った。
ディスクについて、ディスク性能の単位で「rpm」という単位がある。
5000rpmとか、7200rpmなどがあるが、どういう意味だったのか知らなかった。
しかし、今回の事で
1分間にディスク円盤の回転数
だという事がわかった。
確かに、ディスク円盤の回転数が多いと、平均待ち時間が少なくなる。
それに、データ転送速度も上がる。
ディスクへのアクセス時間の早さを知るための指標の一つになる。
ファイルシステムのジャーナル機能
ファイルシステムの世界。どこから攻めても知らない事が沸いて出てくる。
ところで、何気なしに、Linuxのインストールをする際、ファイルシステムは
ext3を選んでいる。理由は、ext2よりもext3の方が
しかし、なぜ良いのか知らなかった (--;;
そこで、何が違うのか調べると、ext3にはジャーナル機能がついているという。
ジャーナル機能って何?
だった (^^;;
調べてみると、こうだった。
| ジャーナル機能とは |
|---|
ディスク障害が起こっても、すぐに復旧できるようにするため
ファイルの更新履歴をログとしてとっておく機能の事をいう。
|
ここで疑問が出てきた。
この場合のディスク障害って何?
ディスク障害というと、ディスク円盤の破損などをイメージしてしまう。
だが、この場合のディスク障害は「破損」とは異なる。
ここでの「破損」はデータの破損の事を意味している。
Linuxや、Windowsが異常終了や停電などで、電源がいきなり切れた時、
書き込んだはずのデータが破損する事がある。
なぜ、そんな事が起こるのかは、ファイルの書き込む際に、
ファイルの書き込む仕組みに原因がある事がわかる。
| ハードディスクへの書き込む仕組み |
|---|
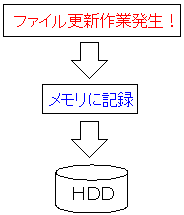 |
ファイルをハードディスクに書き込む際、
直接、ハードディスクへ書き込まれない。
書き込みが発生する度に、直接、書き込むと時間がかかってしまうため
一旦、メモリ(バッファと呼ばれる)へ保存される。
あとで、まとめてデータが書き込まれる仕組みになっている。
もし、メモリ上に保存された状態で
まだ、ハードディスクに書き込まれていない時に電源が切れると、
メモリの内容はぶっ飛んでしまうため
折角のデータがオシャカになってしまう。
|
データの破壊は、一度、メモリ上の保管されたデータをハードディスクに書き込み
できなかっただけではない。
データの書き込む際に、ファイルを管理しているデータ管理部分が
更新されなかったり、中途半端な書き換えにより、データ部分が
行方不明になったりする。
| ブロック構造(ext2のファイルを管理する部分) |
|---|
|
データの管理部分に異常があったり、管理部分のデータが破損してしまうと
読み込みが正常にできなくなる。
|
管理データの部分が破損すると、肝心のデータの位置情報がわからないため、
生きているはずのデータが勝手に「死亡」と判断されてしまう。
そこで、管理データの点検を行なう際、fsckコマンドが使われる。
fsckコマンドを使うという、わかったような書き方をしているが
実は今まで・・・
fsckコマンドの意味を知りませんでした (^^;;
以前から、ファイルシステムの話で出ていたコマンドなのだが、
「ディスクの整合性をとるため」とか「ディスクの点検」といった
説明しか書かれていない場合が多いので、一体、何をするコマンドか謎だった。
今回、初めて、データを管理する管理データが正しいかどうかを点検して
異常があれば修正するためのコマンドである事を知った。
そういえば、Linuxで異常終了した後の起動時に、ディスクの点検が動く。
ファイルシステムが、ext2の場合、fsckコマンドが動いている事は知っていたが、
これで合点がいく。
なるほど、異常終了した後は、管理データの点検をしないと、
肝心のデータが行方不明で「死亡」と決められてしまうからだ。
| ディスクの点検は、あくまで管理データの保全のため |
|---|
管理データを点検したからといって、肝心のファイルの中身が
復活するとは限らない。あくまでも管理データの保全のためだ。
管理データの破壊がひどい場合には、修正が不可能なため、
肝心のデータは行方不明で「死亡」とされてしまう。
管理データ保全は、ファイルシステムの安定稼働を行なう上で、
大事な作業になる。もし、管理データが破壊されると、
全体の整合性がとれなくなり、システムに異常をもたらしたりするため、
システムの安定運用のため、管理データを守るためにできた物だ。
もし、管理データの破壊がひどい場合は、システムの安定稼働を
優先させるべく、肝心のデータを死亡と通知(?)して、
管理データを綺麗に書き換えたりするようだ。
そのため、肝心のデータが守られるという幻想を抱かない方が良いと思う。
|
ところで、fsckコマンドを使うと時間がやたらかかる。
自宅のLinuxマシンは、ext2を使っているため、異常終了をした場合、起動時は
いつもfsckコマンドが動いている。
たった、8GBのハードディスクしか積んでいなくても、イライラしてくる。
それは、ファイルシステム全体の管理データを点検するため
時間がかかるからだ。
ハードディスクの容量が急速に大きくなっているため、どんどん時間がかかるようになる。
そこで、必要な部分だけ点検しようというのが、ジャーナル機能だ。
ext2と互換性を保って、しかも、ジャーナル機能をつけたext3という
ファイルシステムがある。
他の、ReiserFS、JFS、XFSといったファイルシステムにも、
ジャーナル機能が付いている。
ちなみに、私は、会社では、何も考えずに、ジャーナル機能が何かを知らずに、
ただ便利だからという話だけで、ext3を選択していたのだが、
今回の奮闘記のお陰で知る事ができました (^^)
| ジャーナル機能とは |
|---|
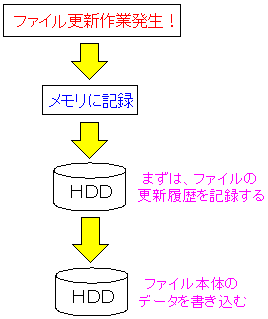 |
データを更新した場合、まず、ファイルの更新履歴のデータを
ハードディスクに記録させる。
そして、後から、肝心の内容のデータを記録させる形をとっている。
|
更新履歴を記録させる利点は、次の通りだ。
| ジャーナル機能の利点 |
|---|
 |
ext2の場合、異常終了後の、起動時に、fsckコマンドが動くのだが、
ファイルシステム全体の点検が行なわれるため時間がかかる。
そこで、ジャーナル機能がついたファイルシステムのでは、
異常終了を起こす前に、記録していたファイルの更新履歴を呼び出して、
異常終了する少し前のデータと該当の管理データ部分を点検を行なう。
そうする事により、点検箇所が少なくなり、時間短縮ができるという。
|
実際に、会社のLinuxマシンが異常終了をした後の起動時に、
ディスク点検を行なうのだが、ext3のジャーナル機能のお陰で働き速い!
あっという間に点検処理が終わる。
ところで、ジャーナル機能で記録されるファイルの更新履歴は、
どこに書き込まれるのか、どんなデータなのか興味が出てくる。
パーティションのルートディレクトリーに.journalであるというが・・・
そんなもん、見つからへん
だった (^^;;
調べてみると、隠れiノードのファイルにしてしまう場合があるため、
その場合は、普通では見えないという。
なんだか、よくわからん、隠れファイルというべきなのか・・・。
でも、ひょんな事から表に出てくる事もある。
ある日、「ext2 → ext3」へのファイルシステムの移行は簡単に事を知った。
早速、実験する事にした。
/sbin/tune2fs -j /dev/hdaX (Xは、パーティション番号)
のコマンドを使い、後は、/etc/fstabのファイルにあるパーティションの情報で
ファイルシステムを、ext2からext3に書き換えるだけでOKという。
極めて簡単! さすがの失敗談生産の私でも問題なくできる作業だ!
ただし、この場合、ルートディレクトリーのパーティションの場合は、
他にも作業がいるようだ。詳しい事は省略します。
もし「省略するな!」という方がいましたら、反論します。
だって、事務員が、そんな面倒くさい作業をする機会がないもーん (^^)
さてさて、簡単にファイルシステムを移行する事ができた。
この時、パーティションのルートディレクトリーを見ると、
| パーティションのルートディレクトリー |
|---|
[root@server]# ls -aF -l
合計 12745
drwxr-xr-x 4 root root 1024 3月 25 17:54 ./
drwxr-xr-x 19 root root 1024 3月 25 16:30 ../
-rw------- 1 root root 8388608 3月 25 17:13 .journal
|
お目当ての .journalファイルがあった!
それにしても、8Mはデカイなぁと思った。
早速、catコマンドで中身を見ると、
バイナリーのため、見られへん (TT)
だった。
中に、どんな記録が書かれているのか、楽しみだっただけに、残念だった。
実は、折角、お目当ての.journalが表に出ても再起動すると
簡単に隠れてしまう。再起動時に、隠す操作が行なわれるからだ。
| カーネルの起動時のログ (一部抜粋) |
|---|
Mar 25 16:30:06 filesys fsck: /var:
Mar 25 16:30:30 filesys kernel: PCI: Found IRQ 11 for device 01:02.0
Mar 25 16:30:06 filesys fsck: Moving journal from /.journal to hidden inode.
Mar 25 16:30:30 filesys kernel: eth0: RealTek RTL8139 Fast Ethernet at 0xc8887000, 00:90:cc:41:ee:93, IRQ 11
Mar 25 16:30:06 filesys fsck: /var: clean, 434/320640 files, 31044/640584 blocks
|
折角、見つけ出したのに、赤い部分で表しているように、隠してしまうのだ。
おそらく、誤って消去されないための配慮なのかもしれないと推測する今日この頃。
|
実際に、自分の目で確認すると、隠れてしまったのだ。
さて、逆に「ext3 → ext2」に戻すのも、簡単にできる。
umount /dev/hdaX で該当のデバイスをマウントから外す。
そして、/sbin/e2fsck -y /dev/hdaXを行なう。
最後に、mount -t ext2 /dev/hdaX /(マウントするディレクトリ)を行なえば完了!
ところで、ファイルの更新を行なう際に、一度、メモリに格納され、
あとで、まとめてハードディスクに書き込むという。
なぜ、ファイルの更新を行なう際に、直接、ハードディスクを更新しないのか。
理由は、CPUやメモリに比べて、ハードディスクの書き込む速度が遅いため、
ハードディスクに書き込む処理が終わるまで待つことになる。
そうなると、アプリケーションなどの動作が遅くなったりする。
そこで、一度、メモリ上に保存して、あとで、まとめて、ハードディスクへ
書き込めば、わざわざハードディスクへの書き込み処理を終わるまで待つ必要が
なくなるため、アプリケーションの動作などが順調に進む。
だが、不測の事態は、いつ起こるかわからない。
高負荷の作業をさせて、異常終了した場合、更新したはずのファイルが
オシャカになる場合も十分に考えられる。
そこで、メモリ上に一時保管されたファイルのデータを強引に
ハードディスクに書き込むためのコマンドがある。
それは、syncコマンドという。
| syncコマンドとは |
|---|
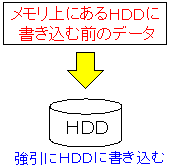 |
|
実際に、syncコマンドを使うと、ハードディスクのランプが点滅するのがわかる。
|
これに似た機能が、PostgreSQLにもある。WALという機能だという。
詳しくは「システム奮闘記:その63」をご覧ください。
(PostgreSQLのお勉強。ログ、WAL、PITR、障害時のデータ復旧)
ファイルシステム ext2 ext3の構造
さて、肝心のデータの記録・保存の方法だが、相当、混乱をした部分だった。
何度も出していますが、ext2(ext3)の場合、ファイルの管理データと
ファイルのデータとの構造は、以下の図のようになっている。
| ブロック構造(ext2 ext3の管理データの構造) |
|---|
|
ブロック図の説明を見ていくと、ディスクの使用状況を管理するため、
ビットマップを利用すると書かれている。
各ブロックごとに、1ビットを割り当てた配列で、使用中を「1」で、
未使用を「0」にして使用状況を表すという。
ところで、iノードテーブルや、データブロックは、同じグループ内に複数個、
存在するのだが、上の図を見ていると、1個だけのように思ってしまう。
そのため、次のような解釈をしてしまった
| 私が誤解した内容 |
|---|
|
スーパーブロック、グループディスクリプタなどの管理データを保管する部分は、
データブロックと同じサイズのブロックとは思わなかった (^^;
雑誌には、ブロックサイズは1K、2K、4Kのどれかを選択されていると
書かれているのだが、この時、私はデータブロックの事だと思い込んでしまった。
この時、1つのグループに、1つのデータブロックしかないと思い込んだため
ブロックグループは大量にあると思ってしまった。
|
さて、1グループに対して、データブロックは(1〜4K)しかないと
とんでもない誤解をしてしまった。
そのため、大きなデータは、いくつかのグループブロックによって
できているのだと思い込んでいた。
ところで、iノードは1対1で、ファイルと対応している。
だが、ファイルシステムを調べていると、Webのサイトの解説で、
iノードの情報は128バイトで、ブロックが4Kの場合、
最大32個のiノードが格納されるという事を知る。
なんで、1つのファイルの複数のiノードがあるねん
と思った。この時「ブロック」は、データブロックとしか頭になかった。
そのため、32個のiノードはデータブロックに格納されると思い込んだ。
編集時には「こんな事を書くと、脚色していると思われるなぁ」と思いながら
キーボードを叩いているのだが、この時は、本気で、そう思い込んでいた。
そのため、ファイルと、iノードが1対1の原則が崩れるため、混乱に陥った。
ふと「1対1の対応関係のiノードって、先頭のデータ部分のiノードでは」と
思った。そして、次のような、とんでもない物を考えついた。
私が誤解を大きく膨らませた内容
ファイルの先頭部分のデータと後続のデータとの関連性 |
|---|
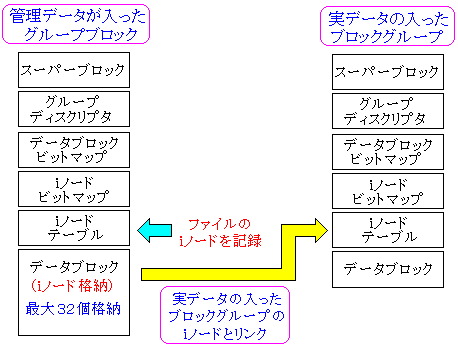 |
そのグループが持つiノードは、iノードテーブルに保管されるが
他のグループとの紐づけのためにあるiノードは、データブロックに保管さて
最大32個のグループとの紐づけができると思い込んだ。
|
とんでもない誤解をしたため、どんどん頭の中が混乱していった。
「誤解」から始まる泥沼地獄。早く「誤解」に気づかないと混乱し続け
時間も労力も無駄にしてしまう。
そこで巨大な助っ人を用意する事にした。
「詳解 Linuxカーネル 第2版」(オライリ─・ジャパン)という本で、
Linuxカーネルに関する分厚い本だ。
その分厚さは、私の三段腹の分厚さと同じくらいだ!
分厚いだけあって、助っ人としての実力も違うため
本に書いてあるブロックの構造を見て、今まで、誤解していた事が一発でわかった。
| ext2、ext3の正しいブロックの構造 |
|---|
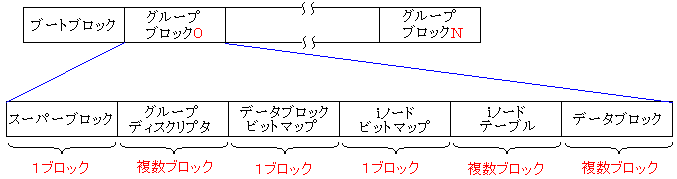 |
この図を見た時、データブロックなどは複数あるのだという事を知った。
今までは、各種ブロックは1つだけだと思い込んでいただけに、
色々、勉強するにつれ矛盾点が出て、矛盾を埋めるようと考えていくにつれ、
抜ける事ができないスパイラルに落ち込んでいった。
しかし、この図を見た瞬間、自分が誤解していた事に気づいたため、
方向修正ができるようになった。
そして、もちろん、全てのブロックが同じサイズで、1〜4Kであることも
この時、初めてわかったのだった。
|
この時、ようやくiノードがiノードテーブルに保管される事を知った。
そういえば、ブロックサイズが小さい場合、ディスクの断片化が起こりやすくなり
ディスクへのアクセス時間がかかるだけでなく、iノードの数が足らなくなる問題が
あるという話を聞いた事がある。
iノードテーブルは複数個持つことができるので数に影響を与えない。
iノードの数に影響を与えるのは、iノードの使用状況の有無を記録している
iノードビットマップだ。これは1グループに1個しか持つ事ができないので、
必然的に1グループが所有できるiノードの数が決まってくる。
「0」か「1」で有無を判定しているため、ビット単位で記録できるため
ブロックサイズに8をかけた数字が、iノードの数になる。(1バイトは8ビット)
| ブロックサイズと格納できるiノードの数について |
|---|
| 1ブロック 1K |
1024×8 = 8192個 |
| 1ブロック 2K |
2048×8 = 16384個 |
| 1ブロック 4K |
4096×8 = 32768個 |
もし、iノードの数が足らない場合は、どんなにディスク領域が空いていても
ファイルと1対1の対応関係ができないため、ファイルが作成できないという。
これから1グループあたりの最大ブロック数が決まる。
理由は、ファイルサイズが1ブロック未満の大きさの場合でも、
1ブロック消費してしまう。
その時、iノードの数だけファイルが作れるので、
理論的に、1パーティションあたりのiノードの数は
(ブロックサイズ) × 8 × (グループブロック数)
となるのだが、実際に使えるiノードの数は、そんなに多くない。
dumpe2fs /dev/hdaXのコマンドを打てば、そのパーティションの情報がわかるので、
実際に見てみると
|
dumpe2fs /dev/hdaXのコマンドを打った結果 |
|---|
Filesystem volume name: /home
Last mounted on: <not available>
Filesystem UUID: 23773e54-7e52-11d8-88f2-c443558dfb38
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: filetype sparse_super
Filesystem state: not clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 359040
Block count: 716892
Reserved block count: 35844
Free blocks: 705611
Free inodes: 359029
First block: 0
Block size: 4096
Fragment size: 4096
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 16320
Inode blocks per group: 510
(途中省略)
Group 21: (Blocks 688128-716891)
Block bitmap at 688128 (+0), Inode bitmap at 688129 (+1)
Inode table at 688132-688641 (+4)
28252 free blocks, 16320 free inodes, 0 directories
Free blocks: 688130-688131, 688642-716891
Free inodes: 342721-359040
|
この時、グループ数は21個あった。
1ブロック4Kなので、1グループで管理できるiノード数は32768個。
単純に計算すれば、32768×21=688128個になる。
しかし、実際には、1グループあたりのiノード数は16320個で
1パーティションあたりのiノード数は、359040個で
理論値(?)の半分ぐらいしかない。
この時、どういう基準でiノード数を決めているのか疑問だった。
|
理論値に比べて、半分のiノード数しか使えない事に、疑問を感じたのだが、
色々、調べても、理由が見つからない。
しかし、iノード数が足らなくなった時の対策法のホームページを見つけた時、
ヒントになる記述を見つけた。
内容は、あるパーティション(/dev/hdaX)で、iノード数が足らなくなった時
まずは、umountコマンドで、マウントを外す。
そして、mke2fs -i 1024 /dev/hdaXコマンドを打てば、
1Kバイトごとに1個、iノード数が割り当てられるという。
何Kごとに、iノードを割り当てているようだ。
また、調べていくと、次の事がわかった。
デフォルトでは、ブロックサイズが1Kの場合、4Kバイトごとに1個の
iノード数が割り当てらる事がわかった。
実際に、自分の目で確かめるべく、ブロックサイズが1Kのパーティションの
情報を見てみる事にした。
| ブロックサイズが1Kのパーティションの情報 |
|---|
Filesystem volume name: /boot
Last mounted on: <not available>
Filesystem UUID: 226f5046-7e52-11d8-80fc-c17322b2ce2e
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal filetype needs_recovery sparse_super
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 124928
Block count: 497983
Reserved block count: 24899
Free blocks: 469223
Free inodes: 124893
First block: 1
Block size: 1024
Fragment size: 1024
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2048
Inode blocks per group: 256
Last mount time: Tue May 11 08:33:09 2004
(途中省略)
Group 60: (Blocks 491521-497982)
Block bitmap at 491521 (+0), Inode bitmap at 491522 (+1)
Inode table at 491526-491781 (+5)
6204 free blocks, 2048 free inodes, 0 directories
Free blocks: 491523-491525, 491782-497982
Free inodes: 122881-124928
|
このパーティションのサイズが497983ブロックなので、497983Kだ。
iノード数は、124928個で、だいたい4Kに1個の割合で
iノードが割り当てられている。
理論値(?)で、8192と比べると4分の1しか割り当てられていない。
このパーティションには、グループ数が60個ある。
|
この結果から、iノード数の初期値が、ブロックサイズの違いなどによって
何Kバイトに1個という割合で決まってくるようだ。
ブロックサイズが4Kの場合、さきほど出した、パーティション情報の結果から、
ブロック数が716892個(716892×4=2867568K)の時、iノード数は、359040個となる。
この事から、8Kに1個の割合で、iノード数が決まってくる。
ブロックサイズの大きさとiノード数だと、話が見えにくいので、
ブロック数とiノード数で、まとめてみると
|
ブロック数とiノードの数の比率(初期状態)について |
|---|
| 1ブロック 1Kの場合 |
4ブロックに1個の割合 |
| 1ブロック 4Kの場合 |
2ブロックに1個の割合 |
となる。見通しが良くなっただけでなく、少し後の話に持っていきやすくなった。
ところで、実際に、mke2fs -i 1024 /dev/hdaXコマンドを使って、
iノード数を増やす事をやってみたのだが、結果は・・・
パーティションが壊れてもうた (TT)
エラーの内容は、次の通りだった。
| エラーの内容 |
|---|
[root@server]# mount -t ext3 /dev/hdaX /boot
mount: 間違ったファイルシステムタイプ、不正なオプション、
/dev/hda1 のスーパーブロックが不正、或いはファイルシステムのマウント
が多すぎます
|
うーん、ext2で行なえば、問題なかったのかもしれないが、ext3でやったので
問題が出たのかもしれない。
仕方なく、諦める事にした (^^;;
iノードの数は、ブロックサイズに依存するため、ブロックサイズが小さいと
iノードが枯渇する話を聞いた事がある。
確かに、ブロック数とiノード数の割合で考えて見る。
|
ブロック数とiノードの数の比率(初期状態)について |
|---|
| 1ブロック 1Kの場合 |
4ブロックに1個の割合 |
| 1ブロック 4Kの場合 |
2ブロックに1個の割合 |
これを見ている限り、1ブロックの大きさよりも小さいファイルが
大量に出来た場合、1ブロック1Kの方が、iノードが不足しやすく思える。
なぜなら、4ブロックに1個しか、iノードが割り当てられないからだ。
だが、今回の実験をしていると、「しかし、待てよ」と思った。
実験では失敗に終わったが、ブロック数とiノードの数の比率の変更が
実際に可能な場合(色々なホームページに方法が書いてあるので、可能だと思う)
1ブロック1Kの場合でも、2ブロックに1個の割合で、iノードが割り当る事が
可能になってくる。
それとプラスして、ブロックサイズが小さいと理論値で示した通り、
1グループで管理できるiノード数は少なくなる事がわかったのだが、
ブロックサイズが小さいと、一つのグループが管理できる
ブロック数も少なくなる。そのため、グループ数も多くなる。
1パーティションごとのiノード数は、次の式で出せる。
1グループでのiノード数 × グループ数
この事を考えると、iノードの数は、ブロックサイズに依存するとは
思えなくなる。
しかし、いくら調べても、この疑問を払拭できる解答が見つからなかった。
事務員の私に解決できるほど簡単な問題ではなさそうなので、諦める事にした (^^;;
ところで、どうやってブロックサイズが1Kのパーティションと
4Kのパーティションを作れたのかと書きますと、実は・・・
偶然の産物なのです
RedHat7.3をインストールした時、パーティションのディスクサイズが小さい場合
自動的に、ブロックサイズが1Kになるみたいだ。
パーティションのディスクサイズが、ある程度の大きさになると4Kになるようだ。
幸い、こういう事を、偶然、発見できたお陰で、実験ができたのだった (^^)
iノードの数の問題を解決(?)した所で、肝心のファイルの中身のデータを
保管する場合、どうやって保管するのか問題になってくる。
iノードはファイルと対の関係にある。つまり1対1の関係だ。
ファイルに関する情報は、iノードテーブルにある。
一つのiノードの情報の大きさは128バイトなので、1ブロック1Kだと8つ、
2Kだと16個、4Kだと32個のiノードの情報が入る。
どんな情報が入っているのか、手っ取り早く知るには、カーネルのソースを
拾い出せば良くわかるので、
| ext2_fs.hファイルより抜粋 |
|---|
struct ext2_inode {
__u16 i_mode; /* File mode */
__u16 i_uid; /* Low 16 bits of Owner Uid */
__u32 i_size; /* Size in bytes */
__u32 i_atime; /* Access time */
__u32 i_ctime; /* Creation time */
__u32 i_mtime; /* Modification time */
__u32 i_dtime; /* Deletion Time */
__u16 i_gid; /* Low 16 bits of Group Id */
__u16 i_links_count; /* Links count */
__u32 i_blocks; /* Blocks count */
__u32 i_flags; /* File flags */
union {
struct {
__u32 l_i_reserved1;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__u32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__u32 i_generation; /* File version (for NFS) */
__u32 i_file_acl; /* File ACL */
__u32 i_dir_acl; /* Directory ACL */
__u32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__u16 l_i_uid_high; /* these 2 fields */
__u16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
|
ファイルに関する情報はiノードテーブルが持っている。
ユーザーIDの番号(uid)、グループIDの番号(gid)
ファイル作成時間、修正時間、データブロック番号(配列)などがある。
|
これを見ていると、アクセス制限や、ファイルの作成時間や、
ファイルの所有者、グループ名など、ファイルに関する全ての情報が
iノードテーブルに格納されているのがわかる。
ここでC言語に関する、少し長い余談
上の構造体の所で「_16」とか「_32」という変数の種類を表す物がある。
おおよそ16ビット整数や、32ビット整数だと予想はしたものの、
全く自信がなかった上、色々、調べても、わからなかった。
そこでLILOのMLに泣きついたら、末廣さんから、次のお返事が来た。
| 末廣さんのお返事 |
|---|
i386の場合、include/asm-i386/types.hで次のように定義されています。
typedef unsigned short __u16;
typedef unsigned int __u32;
|
早速、自分の目で確認すると、末廣さんのおっしゃる通りだった。
「へぇ、そんな設定をしているのか」とわかった気になった私だが、
よく考えると、なんで、わざわざ、こんなややこしい事をするのだろうかと思った。
最初から「『unsigned int』としてしまえば、ええやないか」と思った。
そうすると、丁度良い上野Bさんからは、次のお返事がやってきた。
| 上野Bさんのお返事 |
|---|
__u16 : オブジェクトの大きさが16bitの無符号整数型
__u32 : オブジェクトの大きさが32bitの無符号整数型
の意味になります。
short型が16bit, int型が32bitの処理系でコンパイルするから
「__u16」は「short」であり、「__u32」は「int」なのであって、
いつも単純に「__u16」を「short」に、「__u32」を「int」に読み換えて
いいわけではありません。
例えば、int型が16bit, long型が32bitの処理系では、
__u16 は unsigned int型に、__u32 は unsigned long型になります。
というのも、C言語の規格では、short型やint型が具体的に何ビットなのかは
規定されていません。short型やらint型やらの整数型の大きさが実際に
何ビットになるかは、コンパイラ等の処理系で(ある条件を満たしている限り)
勝手に決めても良いことになっています。
しかし、それでは困ることがあるので、可読性や移植性を考えて、このような
大きさを明示的に指定できるような型を導入することがあります。
わざわざ __u16 や __u32 という型を宣言しているのには、こういう背景が
あるわけです。
|
これを読んで、そういえば、C言語の場合、同じ「int」でも、
コンパイラーやOSなどによって、16ビットだったり32ビットだったりする話を
聞いたような気がした。
ほとんど読まずに(読めずに)ホコリが被ったC言語の本を見ると、
処理系によって、16ビットや32ビットだったりする話が書いていた。
最初からキチンとルールを決めた方が混乱せんで、ええのにと思った。
さて、typedefという物を見た時、どっかで見た事があると思った。
そういえば、構造体の定義を行なう際に、出てきた物だと思い出した。
| よく使う例 |
|---|
typedef struct {
char *title ;
int price ;
char isbn[32];
} BookData
|
上のように定義すると、BookDataが上の構造体の型を表すようになる。そして
BookData *hondata ; で構造体の定義ができ、
hondata->title という使い方ができる。
|
これを知った時、なんだか構造体がわかった気がした。
| 実は構造体をわかっていませんでした (2009/4/1) |
|---|
この時点で構造体について「わかった気」になったが
実際には、わかっていませんでした。
C言語の構造体については「システム奮闘記:その36」をご覧ください。
(C言語入門:ポインタと構造体)
|
そういえば、ファイル操作で身近に使われるFILE *fp;も同じ事なのではと思った。
そこでFILEという構造体の宣言が、どこにあるのか探してみたら、見つかった。
| FILEという構造体の中身 |
|---|
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
int _blksize;
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
|
(注意)
標準ライブラリのglibcのバージョンによって
中身が変わってきますが、当時、どのバージョンで見たのか
失念してしまったため、今となっては、わかりません。
|
なんとか見つけ出したが、中身を見ても、わからなかった (^^;;
でも、この事でC言語の勉強の進展につながったのは確かだった。
ややしこい問題が「宣言」と「定義」の違い。
「宣言」と「定義」の違い
うえのBさんのお返事より |
|---|
JIS規格文では、「6.5.6 型定義」の中で「宣言」の意味で「定義」が
使われてしまっているようです。しかし、「定義」という言葉が使われて
いるのは
「各宣言子は識別子を型定義名として定義する」
「宣言指定子列Tによって指定した型をもつ型定義名として定義する」
の2箇所だけであり、おそらく "typedef" を「型定義」と訳してしまった
ことに起因する訳語の揺れなのではないかと思います。
# 図書館に無くてISO規格まで確認できなかったのが残念。
ちなみに、「宣言」および「定義」という言葉は「6.5 宣言」で次のように
定義されています。
宣言は, 識別子の組の解釈及び属性を指定する。識別子によって
名前付けされたオブジェクト又は関数のために記憶域の確保を
引き起こす宣言を定義(definition)という。
|
「宣言」と「定義」の違い。
私のような事務員から見れば「どっちでも、ええやん」と思いたくなるが
この2つの違いを理解しないと、C言語は理解できないみたいだ。
身近な例がふと浮かんだ。
カツオとマグロ。英語では「tuna」の一言で表す。
欧米人にとっては「カツオとマグロ、どっちでも、ええやん」になるが、
日本人にとっては重要な問題だ。
同じマグロでも、クロマグロ、キハダマグロ、ビンチョウマグロがあるし、
「トロ」の名称は、クロマグロの脂身以外には使ってはいけないため、
ビンチョウマグロの脂身は「トロ」と言わずに「脂身」という。
欧米人にとっては「どうでも、ええやん」が日本人にとって大事な問題になる。
つまり、「宣言」と「定義」を知る事は、C言語の文化(?)を知る事につながる。
うーん、C言語の道のりは、まだまだ遠いなぁと思う今日この頃。
これで、C言語の余談、おしまい
さて、データブロックが配列になっている。
これは通常15個の配列だという。「通常じゃない時は、どういう時やねん」と
突っ込みを入れたくなるのだが、本にもWebサイトにも、この突っ込みに
答えてくれる解答はなかった (^^;;
さて、データブロックの位置情報を記録する部分は15個の配列になっている。
配列には意味があり、巧妙なファイル保管の仕組みになっている。
| データブロック |
|---|
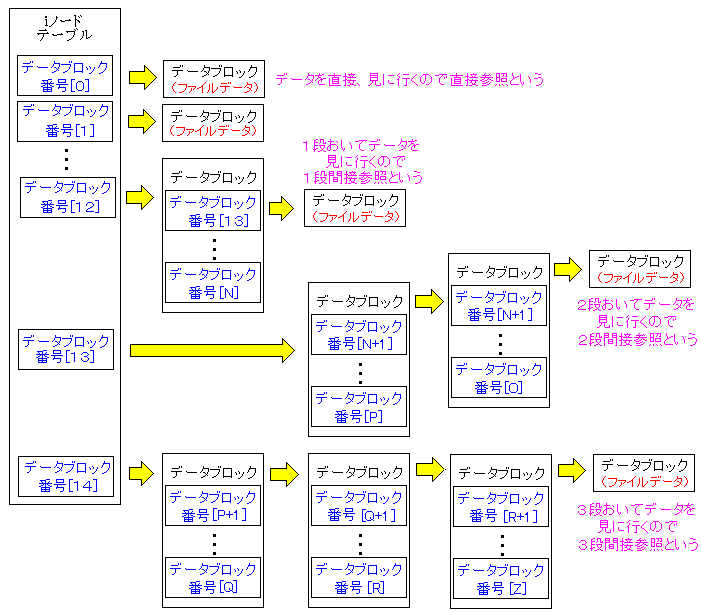 |
iノードテーブルにあるデータブロックの位置情報が記録されている部分の
最初の12個は、直接、データが入ったブロックの位置情報を指している。
直接、データの位置情報を指しているので、直接参照という。
13個目は、ブロックの位置情報を持っているブロックを見に行く。
そのブロックには、実際のファイルデータが入った各ブロックの位置情報が
記録されている。1段階置いているので、1段間接参照という。
14番目は、図の通り、2段階置いて、データの入ったブロックを見るため、
2段間接参照という。
15番目は、図の通り、3段階踏んでいる。データの入ったブロックを見るため、
3段間接参照という。
この辺の説明を上手に書くのは難しい。親カメの上に子カメの例えを考えたが
かえって、混乱しそうなので、止めました (^^;;
|
ところで、言葉や図でファイル保存の様子を書いたとしても、頭の中で具体的な物が、
なかなか思い浮かばない。そこで、実際に、自分の目で確かめたくなる。
この時、debugfsコマンドを使うと、その様子を見る事ができる。
まずは、そのファイルが入っているパーティションを選んで、debugfs /dev/hdaXと打つ。
そうすると、対話型の状態になるので、stat filenameのコマンドを使う。
debugfsコマンドを使った結果
第1段間接参照の場合 |
|---|
debugfs: stat pgCalendar.tar.gz
Inode: 20436 Type: regular Mode: 0644 Flags: 0x0 Generation: 123360132
8
User: 0 Group: 0 Size: 35530
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 72
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x40a853d4 -- Mon May 17 14:55:32 2004
atime: 0x40a853d3 -- Mon May 17 14:55:31 2004
mtime: 0x40a853d4 -- Mon May 17 14:55:32 2004
BLOCKS:
(0-11):86837-86848, (IND):86849, (12-34):86850-86872
TOTAL: 36
|
赤い部分は、12個ある直接参照のブロックだ。
データブロック番号(ブロックの位置情報)は「86837-86848」だという。
青い部分は、13個目の第1段間接参照の最初のデータブロック(位置情報)を
指している。その位置情報は86849だ。
86849の番地のブロックの中には、そこから派生する
各データブロックの位置情報(データブロック番号)が格納されている。
今回は、ファイルのサイズが小さいので、13個が使われている。
その13個のブロック番号は86850-86872が使われている。
|
次に、第2間接参照の場合を見てみる事にした。
少しゴチャゴチャしてくるので、わかりやすくするため、
コマンドの実行結果を少し細工した。
細工といっても、改行部分を変えただけで、実質は同じなのだが・・・。
debugfsコマンドを使った結果
第2段間接参照の場合 |
|---|
debugfs: stat postfix-2.0.20.tar.gz
Inode: 20435 Type: regular Mode: 0644 Flags: 0x0 Generation: 123360132
7
User: 0 Group: 0 Size: 1354414
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 2660
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x40a853c5 -- Mon May 17 14:55:17 2004
atime: 0x40a853c3 -- Mon May 17 14:55:15 2004
mtime: 0x40a853c5 -- Mon May 17 14:55:17 2004
BLOCKS:
(0-11):85507-85518,
(IND):85519, (12-267):85520-85775,
(DIND):85776, (IND):85777, (268-523):85778-86033,
(IND):86034, (524-779):86035-86290,
(IND):86291, (780-1035):86292-86547,
(IND):86548, (1036-1291):86549-86804,
(IND):86805, (1292-1322):86806-86836
TOTAL: 1330
|
赤の部分が直接参照の部分。
青の部分が第1段間接参照の部分。
ピンクが第2段間接参照の部分。
第1段間接参照のブロックが持っている位置情報が256個しかない。
これは、1ブロック1Kのパーティション上でコマンドを使っていたからだ。
|
「百聞は一見にしかず」の言葉の通り、実際のデータの保管状態を
自分の目で見ると、わかりやすい。容易に思い浮かべやすいからだ!
さて、この話を知ると、ext2、ext3の場合、最大ファイルサイズの大きさを
求める事ができる。
データブロックの位置情報は32ビットの正数で表現されている。
32ビットは4バイトになる。
間接参照する事によって、どれくらいのデータを保管できるのかを
1ブロック4Kの場合を考えてみる事にした。
その場合、1ブロックに1024個の位置情報が入る。
| 間接参照とデータの記録可能な量の比較 |
|---|
| 直接参照 |
4K × 12個 = 48K |
| 1段間接参照 |
4K × 1024個 = 4096K = 4M |
| 2段間接参照 |
4K × ( 1024個 × 1024個 ) = 4G |
| 3段間接参照 |
4K × ( 1024個 × 1024個 × 1024個 ) = 4T |
この計算をして、なぜ、ext2、ext3の場合の、最大ファイルサイズが4Tとなる。
(厳密に書くと、4T+4G+4M+48K なのだが・・・)
しかし、矛盾が出てくる。kernel-2.4系だと最大ファイルサイズが2Tであって、
4Tではないからだ。
調べてみると、ページキャッシュの問題などが絡んでいるらしい。
ページキャッシュって何?
しかし、調べる気が起こらなかった。分厚いカーネル本を読む気力が起こらない。
「気合いを入れろ!」と言う方には反論します。
カーネルが理解できれば、事務員辞めて、技術者になっていまーす (^^)
さて、最大ファイルサイズは、わかったが、では、1パーティションあたり
最大何テラまで可能か知りたくなる。本では16Tと書いている。
なぜ、16Tなのか、最初、わらかなかったが、理由は簡単だった。
iノードテーブルにあるデータブロック(データの位置情報)は、
32ビット正数で表現している。
そこで、そこで位置情報の個数と、1ブロックあたりの大きさを掛けると
最大のパーティションサイズが求める事ができる。
32ビット = 4 × 1024 × 1024 × 1024 なので、
4K × (4 × 1024 × 1024 × 1024 ) = 16T
になる。
おっとっと、忘れていた。
ファイルのデータ管理の事は書いたが、ディレクトリの扱いの話もある。
ディレクトリもファイルの一種だと言われている。
確かに、ls -lコマンドを打つと、ディレクトリーだって容量を持っている。
| ls -lコマンドを打つと |
|---|
[root@server]# ls -l
合計 87612
-rw-r--r-- 1 root root 71 Jan 12 00:42 test.dat
drwxr-xr-x 3 root root 4096 Sep 12 2002 picture
drwxr-xr-x 2 root root 4096 Jun 16 2003 genkou
-rwxr-xr-x 1 root root 480 Jun 26 2003 dds.txt
drwxr-xr-x 3 root root 4096 Nov 16 2003 naiyou
|
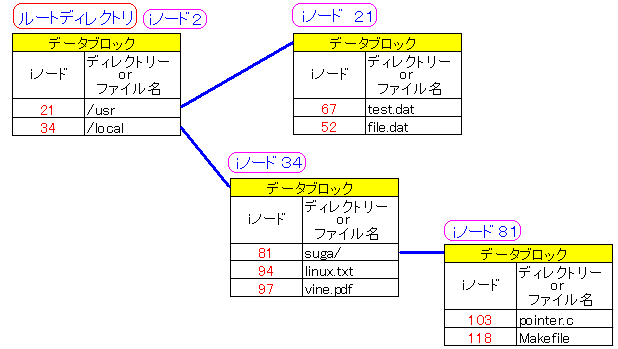
ディレクトリー(ピンクの部分)を見れば、ディレクトリー自身が
4Kの容量を使っているのがわかる。
|
さて、私が1994年に、初めてUNIXに触わって、ls -lコマンドを覚えた時、
ディレクトリーにも大きさがある事を知った。
しかし、なぜ、ディレクトリーにファイルと同様、大きさがあるのか、
10年間の謎だった。
今回、ディレクトリーとiノードの関係を調べると、ようやく10年間の謎が
わかってきた。
| ディレクトリーとiノードの関係 |
|---|
 |
そのディレクトリーにあるファイル名や、すぐ下のディレクトリーの情報は
データブロックの中に格納されている。
ディレクトリーも、ファイルと同様、iノードで管理されている。
ディレクトリーに大きさがある理由だが、ディレクトリー情報を保管するのに、
データブロックを使っている。1ブロック4Kの場合、最低でも4K消費する。
そのため、ディレクトリーにも容量があると表示される。
図では、データブロックが1個のように描いているが、実際には、
データブロックは複数持てるので、沢山のファイルを置いている場合には、
2つ、3つデータブロックを消費する事もあり、8K、12Kになる事もある。
ルートディレクトリーのiノード番号は、ext2、ext3や、古典的なUNIXの
ファイルシステムなどでは「2」になっている。
昔、UNIXの管理関係の処理で「1」を使っていたため、
「2」が、ルートディレクトリーに使われるようになった話がある。
今では「1」は使われていないが、ルートディレクトリーを「2」で
設計してしまっている事から、今更、変更ができない事情があるみたい。
|
10年間の謎が解けて良かったと思った。
それにしても、ファイルシステムは巧妙な作りだなぁと感心してしまった。
WindowsのファイルシステムのFATの仕組み
さて、ディスクの中身について、今度は、Windowsに目を向けてみた。
まずは、FATから調べてみることにした。
| FATの構造 |
|---|
 |
|
ext2、ext3と比べると、単純な構造になっている。
|
予約とは、ディスクの先頭にある領域で、ブートの時などに使われる。
FATとは(File Allocation Table)の略で、ファイルの情報を管理する領域だ。
ここの領域の名前が、そのままファイルシステムの名前になっている。
ルートディレクトリーには、そのドライブの一番上のフォルダ─にある
ファイル名、フォルダ─名を管理する部分だ。
データ領域は、データが入る領域だ。
| FATによるデータの管理方法 |
|---|
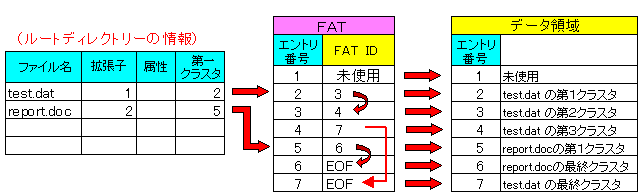 |
ルートディレクトリには、ドライブの一番のフォルダ─にあるファイル名や
そこから派生するフォルダ─名と、第1クラスタの番号(エントリー番号)が
記録されている。
ところで、上の図より、test.datは、エントリー番号2を持っている。
さて、データが第2クラスタ以降もあるのか、どうかの確認も必要になるので、
データを管理しているFATの情報を見に行く。
test.datのエントリー番号は2なので、FATのエントリー番号2と照らし合わせる。
FATには「3」という情報が入っているの、test.datの第2クラスタの
エントリー番号は3になる。
次にFATのエントリー番号「3」を見に行くと、中には「4」という番号がある。
この「4」は第3クラスタの番号を意味する。
そして、FATのエントリー番号「4」を見にいく。すると中には「7」という番号がある。
この「7」は第4クラスタの番号を意味する。
FATのエントリー番号「7」を見にいくと、中には「EOF」が入っている。
これは、ここで最終という意味になる。第4クラスタがtest.datの最終クラスタになる。
FATの中には、test.datのエントリー番号が「2→3→4→7」のように、
数珠つなぎになっている。このような数珠つなぎの事を「クラスタチェーン」という。
|
FATを使う事により、数珠つなぎでクラスタの管理が可能になる。
ディスク上で、クラスタを連続で確保する必要がなくなる。
まぁ、逆に言えば、ディスクの断片化をもたらす要因にもなるのだが・・・。
これを知った時、「なるほどなぁ。単純な仕組みだなぁ」と思った。
散々、ext2、ext3のファイルの管理情報の仕組みを理解するのに、
四苦八苦しただけに、FATの場合は、比較的容易に理解する事ができた。
では、ドライブの1番上のフォルダー以外の、フォルダ─やファイルの管理は
どうやっているのか疑問になってくる。
| 遠隔操作中の画面 |
|---|
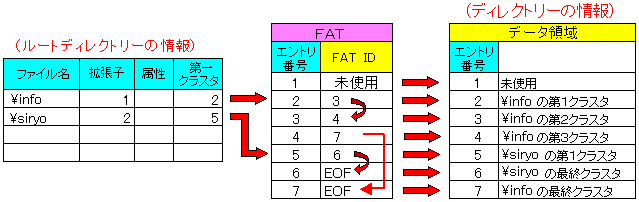 |
infoというフォルダ─のエントリー番号は2になっている。
そこで、FATの情報を見ると、infoというフォルダ─の情報が入ったクラスタは
2→3→4→7のように数珠つなぎになっている。
つまり、infoの中のファイル名や、その下にあるフォルダ─は、infoの情報が
入ったクラスタの中に格納されているという。
そして、infoにあるファイルを見る時は、ルートディレクトリーの情報と同様、
そのファイルの第1クラスタ(エントリー番号)を見て、FATに問い合わせる
仕組みになっている。
ファイルやフォルダ─の位置情報の管理は全てFATで行なわれている。
|
ところで、ドライブの一番のファイル名と、フォルダ─名を管理しているのは
ルートディレクトリーという領域だが、この領域は固定長だ。
そのため、256個しか、ファイル名と、フォルダ─名を登録する事ができない。
しかし、その下のフォルダ─の場合はクラスタ領域で管理されている上、
極端な話、いくらでも数珠つなぎができるので、無限に近い数の
ファイル名と、フォルダ─名を登録する事ができる。
ここで、ファイルシステムの事で、2003年11月に、BLUEのMLで
後藤さんがおしゃった、FATが腐っている3つの理由のうちの、2つ目の理由
FAT のクラスタチェインを用いる管理方式が障害に極めて弱いこと
の意味が、ここにきて、ようやく理解できた。
つまり、ext2、ext3のように、スーパーブロックなどは記録する際、
バックアップとして重複して記録している。
そのため、ディスク障害が起こっても、重複している部分を利用して、
照らし合わせて復旧作業が行なえる。データの保全性は保証できないが・・・。
だが、FATの場合は、FATとルートディレクトリーが情報を管理しているが、
一カ所に集中している上、バックアップがない。
そのため、もし、ルートディレクトリーが破壊されると、何も見えなくなるし、
FATがやられても同じだ。
FATの場合、一部損傷でも、ファイルのよっては数珠つなぎの紐づけが
切れてしまうため、大事なデータが、バラバラ死体のようになってしまう。
WindowsNT系で採用されているNTFSでは、この問題を解消するために
マスタファイルテーブルという管理データをバックアップとして複数持っている。
NTFSについては軽く触れるだけにします。
ここで「手を抜くな! 調べろ!」と言う人がいれば反論します。
だって、良い説明が見つからなかったもん (^^)
色々、インターネットなどを探したが、私が理解できるような説明などが
全く見つからなかった。
そこで「事務員の私は、WindowsNT系のシステムなんぞ組まないもん」と
言い訳して逃げる事にします (^^)
さて、話はFATに戻して、ディスクの不具合を点検するために、
スキャンディスクという物がある。
スキャンディスクには2種類ある。「標準」と「完全」の2つだ。
| Windows98のスキャンディスクの画面 |
|---|
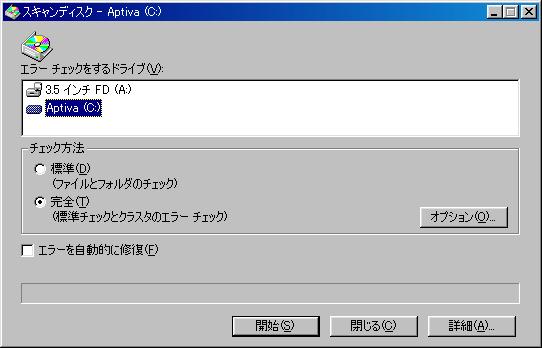 |
この2つの違いは、全く知らなかった。だが、今回の事で、
色々、調べていると、この違いがわかった。
| 「標準」と「完全」の違い |
|---|
| 標準 |
データ管理部分だけを点検する |
| 完全 |
データ管理部だけでなく、全てのクラスタを点検する |
これを知って「なるほど」と思った。
スキャンディスクを行なう際、「完全」で行なうと、メチャクチャ時間がかかる。
今まで、なぜ時間がかかるのか、わからなかったが、全部のクラスタを
点検している事を知り、「そりゃ、時間がかかって当然だ」と思った。
ところで、FATには、FAT16、FAT32がある。
(実は、FAT12もありますが、ここは省略します)
その違いはディスク容量の認識の違いがあった。
FAT16は2G、FAT32は2Tである。
ディスク容量の認識と「16」、「32」とは、大きな関係があった。
FATにはエントリー番号がある。
そのエントリー番号が何ビットという事で「16」と「32」がある。
| エントリー番号の数 |
|---|
| FAT16 |
16ビットの正数の個数 |
| FAT32 |
32ビットの正数の個数 |
まずは、FAT16から見ていく事にする。
16ビット正数は、2の16乗なので、65536になる。
65536個のエントリー番号を持ち、それだけの数のクラスタ管理ができる。
FAT16の場合、1クラスタは32Kになる。
そこで、最大、どれくらいのディスク容量を認識できるか計算すると
32K × 65536 = 2G
と出てくる。本に書いてある通り、2Gが出てきた。
次に、FAT32から見ていく事にする。
32ビット正数は、2の32乗なので、4294967296だ。
(4 × 1024 × 1024 × 1024)
凄い数のエントリー番号を持ち、それだけの数のクラスタ管理ができる。
FAT32の場合、1クラスタは4Kになる。
そこで、最大、どれくらいのディスク容量を認識できるか計算すると
4K × 4294967296 = 16T
と出てくる。本に書いてある、2Tと違った値が出てきた。思わず
なんで、違うねん (TT)
だった。
調べてみると、FAT32の場合、実際には28ビットしか使われていない。
しかし、どう考えても28ビットだと次の計算になってしまう。
28ビット = 256 × 1024 × 1024
4K × 256 × 1024 × 1024 = 1T
よく考えると、FATの場合、パーティションサイズで、
クラスタのサイズが変わる。32G以上は、32Kだ。
しかし、それで計算しても、結果は、8Tになってしまい、2Tにならない。
色々、調べてみたが、私に理解できる解説は見つからなかった (--;;
マイクロソフトのやる事なので、理解不能な事をしてくれるのは、
いつもの事なので、あまり気にならない。
身近なWindows98に使われているファイルシステムのFATなのだが、
今回の事で、知らない事だらけだなぁと思った (^^)
ここで、後藤さんがおっしゃったFATが腐っているの、2つ目の理由
「大容量ディスクの取扱いに難があること」の理由がわかった。
FATの場合、2Tしか扱えないため、大容量ディスクを使っても無意味な事だ。
ディスクパーティションを行う理由
ディスクパーティション。
なぜ、ディスクパーティションを行なうのか、謎のままだった。
「システム奮闘記:その9」では、パーティションによって、
実行ファイルを、ファイルの所有者の権限で実行できる
suidとsgidの存在を許可するかどうかの
設定できるため、セキュリティー上、必要だと書いた。
しかし、それは、あくまでも1つの理由だという事がわかった。
パーティションを分ける理由には、他にも主に3つある。
| パーティションを分ける理由:その1 |
|---|
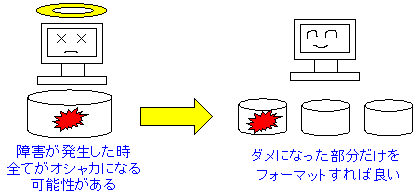 |
異常終了などで、ディスク障害が起こった場合、パーティションが1つだと
下手をすると全てオシャカになる可能性がある。
そこで、複数にわけて、1カ所、障害が発生しても、他の部分に影響が出ないよう
リスク回避するためにある。
|
| パーティションを分ける理由:その2 |
|---|
 |
バックアップを取る際、パーティションを丸ごと取る事がある。
頻繁に内容が書き変わるため、頻繁にバックアップをとる必要がある場合と、
あまり必要がない所がある。
そのため、頻度に応じて、バックアップをわけて取るのが効率的だ。
また、丸ごとバックアップの場合、パーティションが1つだと、
容量的に巨大になるが、わける事により、分割してバックアップが取れる
利点が出てくる。
|
| パーティションを分ける理由:その3 |
|---|
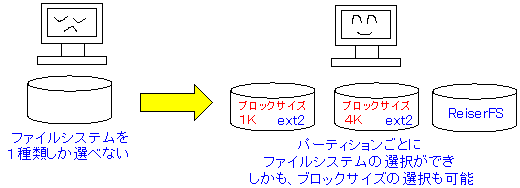 |
各パーティションごとに、ファイルシステムが選べる。
/varのようにログの書き込みが頻繁な所や、小さいファイルの書き込みが多い所には、
ReiserFSで、他は、ext2、ext3という風に、用途に合わせて、
パーティションごとに、ファイルシステムを設定する事ができる。
|
「システム奮闘記:その9」のセキュリティーの話を含めると、
パーティションを行なう理由は、主に4つとなる。
Linuxを触って4年経って、ようやくパーティションをする理由がわかった (^^)V
ここで暴露!
パーティションを行なう理由について調べている時だった。
たまたま、ファイルの数が増えると検索時間がかかるという話を目にした時、
どう勘違いしたのか、「ハードディスクのサイズが大きくなれば、検索時間が増える」
と思い込んでしまった。
そのため、パーティションを分割するは、パーティションを一つにしてしまうと
ファイル検索が遅くなると結論づけたのだった (^^;;
|
パーティションを分ける理由(私の勘違い) |
|---|
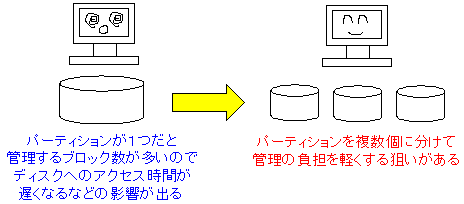 |
実は、パーティションを行なう理由に、この勘違いを載せる所まできていた。
しかし、下手に載せて「突っ込み」が来る可能性があるので、念のため、
色々、調べてみたが、この手の話は見つからない。
「全くウラがとれへんなぁ」と思っていた時に、ファイルの検索速度が遅くなるのは
ディスクの容量ではなく、保有しているファイル数によるものだという事で、
自分が誤解している事に気が付いた。
誤解と書いたが、よく考えると、完全に、間違いとは言いがたい。
なぜなら、パーティションを分けることにより、1つのパーティションが管理する
ファイルの数が減るため、ファイルの検索速度が早くなる事が考えられる。
ただ、ウラがとれないだけに、何とも言えないのが現実・・・ (--;;
ここで体験者からのアドバイス!
パーティションをする際は、ディスクサイズを気をつけるように!
というのも「システム奮闘記:その9」で触れていますが、
パーティションのサイズを小さくしてしまったために、
ディスクをパンクさせた経験があります (^^;;
これは具合いが悪いので、気をつけてくださいね!
パーティションを行なう理由に、パーティションごとのバックアップができる事を
とりあげた。
ところで、どうやってパーティションごとのバックアップをとるのか。
その答えは、2004年のSoftDesign3月号に載っていた。
dd if=/dev/hdaX of=/home/backup.imgのコマンドを叩くと
hdaXのパーティションのバックアップが、/homeのディレクトリー内に
backup.imgという名前のファイルで作られるという。
パーティションごとのバックアップは、定期的にデータを保管する目的以外にある。
fsckコマンドを使って、ディスクの整合性のチェックを行なう際にも、
整合性のチェックをかけるパーティションのバックアップをとる事が勧められている。
理由は、ファイルシステムに不整合が見つかった場合、最悪の場合、
中身が消えてしまう危険性があるため、安全のためバックアップをとる事が
勧められている。
本には、マスターブートレコードがダメになっても、大丈夫なように
マスターブートレコードのバックアップの方法が書かれていた。
その前に、マスターブートレコードって何? (^^;;
| マスターブートレコード(MBR) |
|---|
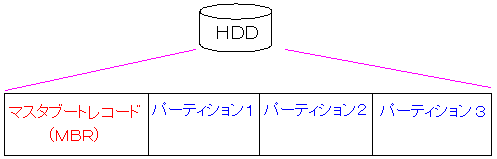 |
まず、パソコンが起動する時、最初にBIOSが動く。
そして、BIOSがハードディスクの先頭にあるマスターブートレコードを読み込む。
マスターブートレコードには、ハードディスク内にあるパーティションのサイズや
ディスク上の位置が記録されている。
OSが立ち上がるのは、マスターブートレコードが、各パーティションの中で、
起動フラグが立っている物を選んで、先頭のブートセクタを読み込むため
OSが起動する。そのため、大事な役目をするものだ。
もし、マスターブートレコードが壊れると、パーティションの位置がわからず
OSが起動しなくなる。
マスターブートレコーダーについて詳しくは
「システム奮闘記:その71」をご覧ください。
(Linuxのブートローダー・GRUBの設定)
|
ハードディスクの先頭の512Kバイトがマスターブートレコードに
割り当てられている。そこで、
dd if=/dev/hdX of=boot.img bs=512 count=1
のコマンドを打つと、デバイス名(/dev/hdX)のマスターブートレコードの
バックアップを、boot.imgというイメージファイルを生成してくれる。
bsは、1度に読み書きするバイト数を意味する。
そして、countは、bsで指定したサイズを何ブロック読み書きするかの意味だ。
イメージファイルって何?
そういえば、「システム奮闘記:その23」でも触れたが、CD-RWに焼く時
焼きたいデータを、イメージファイルに変換してからCD-RWに焼いている。
CD-RWに焼き付けるための、独特のデータ形式なのかなぁと思っていたが、
調べてみると、次のようなファイルだった。
CD-RWやディスクのデータ構造を、そのままファイル化した物だという。
だから、何?
しかし、調べても、納得いく解答が見つからない。
ところで、UNIX(Linux)では、デバイスもファイルという概念だ。
すなわち、ハードディスクのデバイス(/dev/hdX)があれば、
それ自体もファイルだという。
以前から、その話は知っていたが、「へぇ〜」というだけで、その時は、
何も関心も示さなかった。
だが、今回、それに関するホームページを見つけて、catコマンドで、
デバイスごとコピーをかける話が書いてあった。
「百聞は一見にしかず」なので、小さなパーティションのデバイス名で
cat /dev/hdaX > dev.datという感じで実験したら、見事にファイルができあがった。
ふと思った。
ddコマンドと同じ役目をするのではないか?
物は試しで、dd if=/dev/hdaX of=/dev2.imgでファイルを作ってみた。
そして、ファイルのサイズを比較したら一致した!!
ファイルサイズが一致は偶然かもしれないので、uuencodeでASCIIコード化して
diffコマンドで中身の比較を行なったら、見事一致した!!
実に、面白いもんを発見したなぁと思った (^^)V
デバイスもファイルという考えがUNIX(Linux)にはあるが、
この実験で、次のような事だと思う。
| デバイスもファイル |
|---|
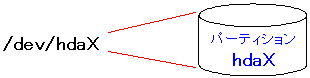 |
図のように、ハードディスクを表すデバイスは、パーティションの部分
そのものを表したファイルではないかと思う。
そのため、cat /dev/hdaX > file.imgを使って生成されたファイル(file.img)は、
パーティションそのものをコピーしたからだと考えられる。
それに付け加えて生成されたファイルのサイズを見てみると、
パーティションの大きさに近いサイズのファイルが出来上がる。
これは、ディスクパーティションのデータ全てを、ファイルの形にしたため
だと考えられる。
なかなか、奥が深い話だなぁと思った。
|
この事から、イメージファイルとは、ファイルシステムなどを通したデータではなく
ディスクににあるデータそのものだという事が言えるのではないかと思った。
ディスクフォーマットの話
今回、ファイルシステムの勉強をして、身近だが意外と知らない事を発見した。
それはディスクフォーマットの話だ!
昔、フロッピーディスクを買った時、フォーマットを行なう必要があった。
フォーマットにも、PC98用とDOS-V用があり、フロッピーの容量も
1.2Mと1.4Mだった。7、8年くらい前の話だ。
最近のフロッピーディスクはフォーマット済みのが売られているが、
古いフロッピーディスクは、読み書きできなくなっている事があるので、
フォーマットを行なっている。
もちろん、LinuxやWindowsをインストールした際に、ディスクパーティションを
行なった後、自動的にインストーラーが、フォーマットを行なってくれる。
それだけフォーマットが身近な作業だという事を意味する。
だが、「フォーマットは何をする作業なの?」と聞かれると思わず
ドキッ!
となる (^^;; ← つまり知らないという事を意味するのだ。
今まで、フォーマットが具体的に、どういう作業の事なのか、知らなかったが、
今回のファイルシステムの勉強中に、偶然、見つかった問題だった。
フォーマットには物理フォーマットと論理フォーマットがある。
この時、フォーマットに物理と論理がある事を初めて知った。
| 物理フォーマットとは |
|---|
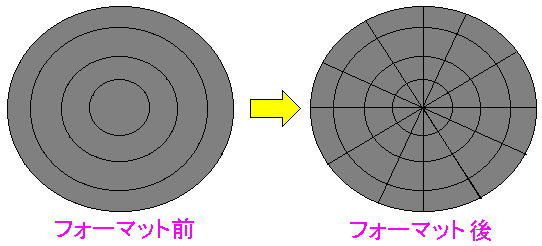 |
ハードディスクやフロッピーディスクがフォーマットされる前は、
円盤の所はトラックのみがある状態だ。
物理フォーマットとは、データを入れるための最低の区画(セクタ)を
ディスク円盤上で、割り当てる作業の事をいう。
|
これを知って、フォーマット時にセクタが作られるのかぁと思った。
次に論理フォーマットの場合は
| 論理フォーマットとは |
|---|
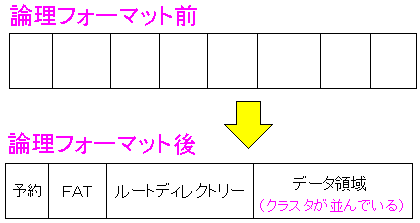 |
FATの場合を例にとってみました。
物理フォーマットでセクタが区切ったが、それだけではデータの読み書きができない。
そこでデータの読み書きが可能になるように、ブートするための領域や
ファイルなどのデータを管理する領域(FAT)を確保して
実際に、データのやりとりができるように整備する事をいう。
|
実際に、この2つの違いは、どこで使い分けているかが問題になる。
Windowsでは「通常のフォーマット」と、「クイックフォーマット」がある。
| Windows98でのフォーマット画面 |
|---|
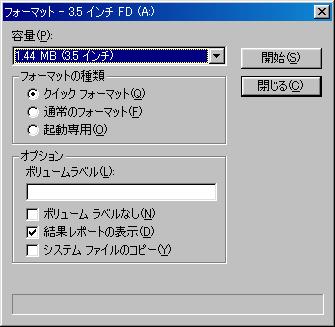 |
通常のフォーマットは、物理フォーマットと、論理フォーマットを行なう。
クイックフォーマットは、論理フォーマットだけを行なう。
すでに、ディスク円盤上でセクタごとに分割ができている場合は、
クイックフォーマットだけを行なえば良い。
といっても、具体的に、どういう時なのかが、わからない・・・ (^^;;
ただ、言える事は、現在、使っているフロッピーディスクの中身を消して
中身を空にしたい場合は、すでにセクタの区切りができてきるので、
クイックフォーマットだけを行なえば良い。
ただし、論理フォーマットは、ブートする部分やデータ管理部分だけ書き換えで、
ファイルのデータの入ったクラスタは死んではいないので、これを行なった後、
消えたと思って安心してディスクを外部へ流出すると、情報を取り出され、
情報漏洩につながる、こわーい話が成り立つ (^^;;
ReiserFSの簡単な話
さて、最後に、今後、Linuxで標準になるであろうファイルシステムについて
触れたいと思います。
そのファイルシステムは、ReiserFSと言われています。
特徴は、ファイルの検索が早い、書き込み、読み込み速度が速い事、
iノードの枯渇の問題がない事、小さなファイルの保管に向いている等がある。
さっそく、会社の実験サーバーにインストールしてみる事にした。
公式ホームページ(http://www.namesys.com/)から、reiserfsproga-3.6.4をダウンロードした。
そして、展開して、configure、make、make install を行なっていった。
次に、ReiserFSに変更したいデバイス(私の環境では /dev/hda2)を、
umount /dev/hda2 で外した。
そして、mkreiserfs /dev/hda2を実行した。
|
df -i -Tコマンドでiノードを見ると |
|---|
root@filesys root]# mkreiserfs /dev/hda5
mkreiserfs 3.6.17 (2003 www.namesys.com)
A pair of credits:
Chris Mason wrote the journaling code for V3, which was enormously more useful
to users than just waiting until we could create a wandering log filesystem as
Hans would have unwisely done without him.
Jeff Mahoney optimized the bitmap scanning code for V3, and performed the big
endian cleanups.
BigStorage (www.bigstorage.com) contributes to our general fund every month,
and has done so for quite a long time.
Guessing about desired format.. Kernel 2.4.18-3 is running.
Format 3.6 with standard journal
Count of blocks on the device: 716880
Number of blocks consumed by mkreiserfs formatting process: 8233
Blocksize: 4096
Hash function used to sort names: "r5"
Journal Size 8193 blocks (first block 18)
Journal Max transaction length 1024
inode generation number: 0
UUID: 22f2ef6b-54a5-4b98-81a1-024381898c82
ATTENTION: YOU SHOULD REBOOT AFTER FDISK!
ALL DATA WILL BE LOST ON '/dev/hda5'!
Continue (y/n):
|
|
色々な事が英語で書かれている。もちろん、読む気は起こらない (^^;;
最後の部分で「Reiserfsに変更する/dev/hda5のデータが消えてもええか?」と
尋ねてくる。もちろん、大丈夫なので「Y」を選ぶ。
そうすると、意外と短時間で、下の作業を行なってくれる。
|
Continue (y/n):y
Initializing journal - 0%....20%....40%....60%....80%....100%
Syncing..ok
Tell your friends to use a kernel based on 2.4.18 or later, and especially not a
kernel based on 2.4.9, when you use reiserFS. Have fun.
ReiserFS is successfully created on /dev/hda5.
|
ファイルシステムを入れるのに成功したと表示された。
そして、mount -t reiserfs /dev/hda5 /homeで、マウントした。
見事に、ReiserFSの導入は成功した。
早速、適当な、tar.gzファイルを展開してみたら、気のせいか、展開の速度が速い。
もちろん、定量的に測定したわけでないので、断言はできないが、
ファイルの書き込みや読み込みが速いという話は、本当のようだ。
iノードにも特徴があるという。動的iノードを採用しているという話だ。
グループブロックごとに固定数のiノードのではなく、別の管理方法をしているため
枯渇する心配がないという。
|
df -i -Tコマンドでiノードを見ると |
|---|
[root@server]# df -T -i
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/hda8 ext3 102800 20415 82385 20% /
/dev/hda1 ext3 124928 35 124893 1% /boot
none tmpfs 15695 1 15694 1% /dev/shm
/dev/hda9 ext3 38152 90 38062 1% /tmp
/dev/hda5 ext3 384000 88221 295779 23% /usr
/dev/hda7 ext3 320640 601 320039 1% /var
/dev/hda6 reiserfs 4294967295 0 4294967295 0% /home
|
他のファイルシステムよりもケタ違いにiノードの数が多い。
でも、待てよと思った。ReiserFSの部分にはファイルを入れているのに、
使われているiノードの数は「0」になっている。奇妙な話だ・・・。
|
ext2、ext3と違いを見せつけられた感じがした。
他にも、小さなファイル保管に向いている理由は、
ext2、ext3だと、ブロック単位でファイルの管理をしているが、
それだと無駄な領域ができる。
そのため、ReiserFSでは、ファイルを入れる領域を固定ブロックをやめたという。
さすがに、詳しい事までは、わからないが、凄いなぁと感心した。
さて、いくらファイルシステムの変更ができたと言っても、
リブートした後で、自動的にマウントしてくれないと、導入に成功とは言いがたい。
そこで、fstabファイルを次のように書き変えた。
| fstabファイルの書き変える前 |
|---|
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
LABEL=/home /home ext2 defaults 1 2
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
/dev/hda9 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
|
| fstabファイルの書き変えた後 |
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
LABEL=/home /home reiserfs defaults 1 2
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
/dev/hda9 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
|
ご存じの方は、これだとエラーが出るぞと思われるでしょう。
実は、あまりfstabファイルの設定の意味を知らなかった事を暴露します (^^;;
|
これで、問題なくリブートしたら、立ち上げるだろうと思ったら、
起動時にコケてもうた (TT)
なぜ、コケたのか理解できなかった。
そこで、googleで調べると、fstabファイルの5番目、6番目の項目を「0」に
すれば良いと書いてあった。
そこで、fstabファイルを次のように書き変えた。
| 書き変えた部分のみ抜粋 |
|---|
LABEL=/home /home reiserfs defaults 0 0
|
最後の数字に部分を「1 2」から「0 0」に変えた。
この時、数字の意味はわからなかった。
|
そうすると、リブートの途中でコケる事はなくなったが、エラーがでて、
マウントしてくれなかった。
そして、また、googleで調べる事にあった。
色々、調べてみると、LILOを使うとダメな感じがしてきた。
GRUBを使うような感じがしてきた。
そんな勝手な思い込みをし始めたため、次のようなデタラメな結論を出した。
LILOだと、マウントしてくれない
LILOからGRUBへ移行する簡単な方法がわからないので、
OSの再インストールから始めた。
そして、ReiserFSも入れ、fstabも書き変えて、リブートをしたが・・・
やはりエラーがでる (TT)
ドツボにハマった感じがした。こういう時、悪魔のささやきがやってくる。
「どうせ、使わへんねんから、この辺りで、諦めたら、どうや」
悪魔のささやき。奮闘記を書いていたら、よく耳にする。
分量の少ない場合だと、編集に時間がかからない上、労力もかからないので、
悪魔のささやきは撥ね除けるが、今回の膨大な量を編集したりしていると、
「もう、疲れた。この辺で妥協した方が賢いなぁ」と思う事がよくある。
しかし、往生際の悪い私は、原因を調べる事にした。
次に、目をつけたのはカーネルの再構築だった。
後で、わかった話だが、RedHat7.3の場合、カーネルの再構築をする必要はない。
だが、そんな事を知らない私は、googleで、カーネルの再構築の話を書いている
サイトを見て「これだ!」と思った。
そして、早速、カーネルの再構築を行なった。
カーネルの再構築の画面(ReiserFSの選択)
初期状態ではモジュールの「M」が入っていたので、取り込む事にした |
|---|
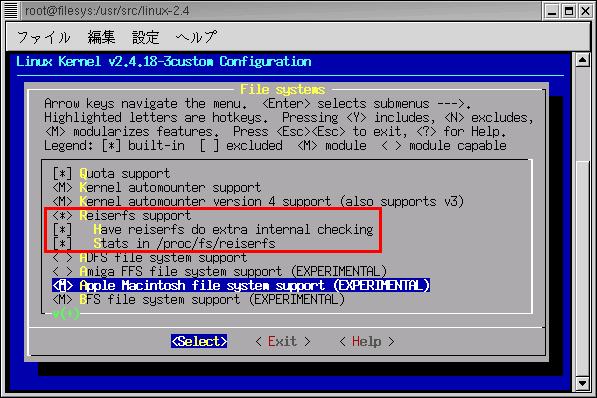 |
これで大丈夫だろうと思って、カーネルの再構築。
そして、ReiserFSを入れて、いよいよリブート実験を行なったら・・・
それでも、認識してくれへん (TT)
万事休す。もう、打つ手なし。ここは、悪魔のささやきに従って、
事務員には難しすぎて、わかりませーん (^^)
という常套手段で逃げようと考えた。しかし、ふと「待てよ」と思った。
そこで、fstabファイルを調べると「おやっ?」と思った。
| fstabファイルの内容 |
|---|
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
LABEL=/home /home reiserfs defaults 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
/dev/hda9 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
|
普通ならデバイス名が記入されている所に「LABEL=/home」になっている。
そこで、下のように、デバイス名に書き変えた。
|
| fstabファイルを、さらに書き変えた |
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
/dev/hda5 /home reiserfs defaults 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
/dev/hda9 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
|
これで大丈夫だろうと思って、リブートした。すると・・・
見事に成功した!!
やれやれと思った。
念のため、カーネルを再構築する前の環境で、リブートの実験を行なったら
問題なく成功した。
もちろん、LILOで動く事も確認した。大ウソを書かずに済んだ (^^;;
結局、私がfstabファイルに体する認識不足が原因だった (^^;;
さて、fstabファイルについて調べてみた。
| fstabファイルの内容 |
|---|
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
/dev/hda5 /home reiserfs defaults 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
/dev/hda9 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
|
青の部分を見ていく事にした。
LABEL=/bootは、ラベルが「/boot」という意味だ。
本来、この部分はデバイス名が入るのだが、ext2、ext3、xfsの場合、
デバイス名が変更になっても、ラベルで認識できるように、
デバイス名の代わりにLABEL=/bootが使えるという。
次に、マウントするディレクトリ。ここでは/bootになっている。
その次はファイルシステムの名前が入る。
その次のdefaultの意味だが、これも複雑だ。
これは、マウントのオプションで、いくつかのオプションをまとめた物になる。
具体的には、async、dev、exec、nouser、rw、suidを一緒にしたオプションが
defaultになっている。
ちなみに、asyncは、ファイルシステムに対しての全てのI/Oが
非同期に行なわれるという意味だ。うーん、理解できない・・・ (--;;
devも、ファイルシステム上のキャラクター・スぺシャル・デバイスと
ブロック・スぺシャル・デバイスが利用できると書いているが、理解できない (--;;
だが、execは、バイナリーのファイルの実行可能だというのは、すぐにわかった。
nouserは、このデバイスはルート以外の一般ユーザーにはマウント不可も、わかる。
もちろん、rwが、読み書き可能なパーティションだというのも、わかる。
最後の、suidは、ファイルの所有者、または所有グループの権限で動く
実行ファイルを認める事もわかる。
5番目の「1」の意味は、dumpコマンドに由来するが、わかりませんでした (--;;
6番目の「2」は、fsckコマンドに由来するものですが、わかりませんでした (--;;
ただし、「0」の場合は、fsckのチェックをしない意味になる。
|
うーん、fstabファイルに込められている意味は深いなぁと染々と感じた。
ところで、ReiserFSのファイル検索が高速な理由は、検索方法に「B*木」という
方法を使っているからだという。
「B*木」って何?
「B木」の派生タイプというが、もちろん「B木」ですら何か、わかっていない。
これも調べようとしたが、何せ今回のシステム奮闘記を編集をするのに、
膨大な情報を調べていたため、力尽きていていたため、調べる気力がなかった (^^;;
ちなみに、WindowsのNTFSのファイル検索は「B+木」という方式で、
こちらも高速だという。
最後の最後で、VFSについて取り上げていなかったので、
ほんの少し触れることにしました。
1台のマシンで、Linux、Windowsと同じディスクで共存する事ができる。
その時、Linux側から、マウントすれば、Windows側のデータを見る事ができる。
その他、ext2、ext3、ReiserFS、xfsなど、色々なファイルシステムとを
共存させる事ができる。
共存できる理由には、VFSという仮想ファイルシステムがある。
| VFSについて |
|---|
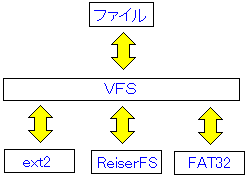 |
ファイルを、各ファイルシステムにアクセスする時、仲介役を行なうのがVFSだ。
各ファイルシステムが共通に持っている部分を肩代わりして
個々のファイルシステムに依存する物だけを特化させる仕組みをとっている。
その事によって、各ファイルシステムは、共通部分をVFSに任せて
それぞれの機能強化を行なえるようにしているという話だ。
ところで、VFSは、元々はSunが出したもので、それが各OSに広がっているという。
|
VFSに関して、少し突っ込んだ話を書きたいと思ったのだが・・・
ここで力尽きました (--;;
大気圏に突入したが、燃え尽きてしまった感じだ。
VFSに関しては「ファイルシステムのお勉強:第2弾」で取り上げたいと
思います。
まとめ
ファイルシステム。調べ出すと、色々、わかっていなかった事や
誤解していた事などが噴出。
噴出した時点では「へぇ、そうだったのか」と新しい事を覚えて喜ぶのだが
編集の時点になると「うげー」となった。
私の2003年10月時点で、私の知りたかった事は、今回の事で解決できました。
何を知りたかったのかを表にしますと以下の通りです。
| ファイルシステムについて、私が知りたかった事 |
|---|
| (1) |
ファイルシステムとは何か |
| (2) |
ファイルシステムの障害は、どんな事なのか |
| (3) |
fsckコマンドは何をするコマンドなのか |
| (4) |
ファイルシステムの障害対策の方法 |
以上の4点でした。
この4点に関しては、自分なりには理解できたと思います (^^;;
しかし、今回の事で、課題を残してしまった。
ReiserFSの仕組みを調べる事。NTFSの仕組みを調べる事や
VFSについても、具体的に、どんな働きをするのか調べてみたいです。
最後に、ファイルシステムの良い入門書がないだけに、この奮闘記が「入門書」に
なればと願うばかりです。
次章:「メールサーバーソフト Postfixの設定」を読む
前章:「みんなのカレンダー」を読む
目次:Linux、オープンソースで「システム奮闘記」に戻る