システム奮闘記:その83
cups-pdfでPDFファイルの生成
(2009年12月12日に掲載)
社内でのPDF変換の歴史
PDFファイルだと、AcrobatReaderを入れているパソコンだと
簡単に閲覧できる。しかも無償で見れるのだから便利だ。
2003年頃だった。本社にパワーポイントを使っている人がいた。
その人が全営業所にパワーポイントで作成した資料をメールで配布
営業所のパソコンにもMS-Officeを入れているのだが
ワード、エクセルだけなので、もちろん営業所から
ファイルが開かれへんで
という苦情がやってきた (--;;
そのためAcrobatを購入し、パワーポイントで作成した資料を
事前にAcrobatでPDFファイルに変換する事になった。
Acrobatを購入したお陰で、他の使い道を発見した。
ワード、エクセルのソフトは、異なるバージョンで読むと
位置がずれたり、図が表示されなかったりする。
同じソフトでありながら、バージョンが異なると
表示に不具合が出てくるため・・・
非常に迷惑な話なのだ!!
こんな時・・・
おどれ、MS、なめとんのか!
とナニワの帝王に負けない怒鳴り方をしたくなるのだ。
Acrobatは1本しか買っていないため、不便だった。
新しいバージョンのAcrobatが出た時、パソコン好きの部長が購入。
部長が資料配布のためにAcrobatでPDF変換すると同時に、
最初に買ったAcrobatをみんなが使うパソコンに入れて
共同利用になった。
OpenOfficeでPDF化
OpenOfficeを使えば、無料でワード、エクセルをPDF変換ができる。
非常に便利なのだが、当時はOpenOffice2.x時代。
なので・・・
互換性に問題があったのらー!!
この時は、ワード、エクセルの表示のズレが起こったりしていたので
あまり実用的ではなかった。
だが、OpenOffice3.0が出た時・・・
これでPDF変換が無料でできる!!
と喜んだ。
ワード、エクセル以外のファイルについて
OpenOffice3.0が出たお陰で、表示のズレが目立たなくなった。
そのお陰で、PDFファイルに変換しやすくなった。
だが、まだ課題があった。
ワード、エクセル、パワーポイント以外のファイルは
PDF変換ができへん (TT)
無料のCADソフトがあるが、営業所では開けない。
PDF変換できれば良いが、それができないため、本社で印刷して
それをFAXと郵送で営業所に送っている。
FAXだと細かい図面を送ると、綺麗に送信できない上、
郵送だと手間と時間もかかるので、効率が悪い。
cups-pdfとインストールと設定
2009年9月、LinuxとCUPSの組み合わせで
プリンターサーバーの構築を行った。
詳しくは「システム奮闘記:その82」をご覧ください。
LinuxとCUPSでプリンターサーバー構築
そんな時、色々なcups関係のサイトをみていくと・・・
CUPS-PDFを発見したのらー!!
これを使えばPDF変換が無料でできる。
| cups-pdfとは何か |
|---|
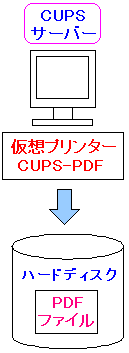 |
cups-pdfとは仮想プリンターの一種だ。
この仮想プリンターを使って印刷作業を行うと
PDFファイルが生成される仕組みだ。
|
ふと思った。
Sambaと組み合わせれば、エエかも!
そこで以下の事を考えた。
| cups-pdfとSambaの組み合わせでPDF変換システム |
|---|
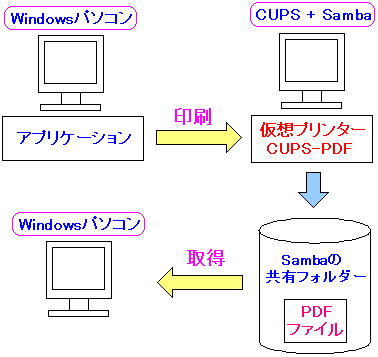 |
Windows側でPDF変換したい部分を印刷を行う。
CUPSサーバーで、印刷データを受信し、仮想プリンターの
cups-pdfでPDF変換を行う。
生成したPDFを簡単にWindows側から取り込めるように
Sambaを使って共有フォルダーに作成し、その部分に
生成したPDFファイルを落し込む形にすれば便利なのだ
|
Sambaはファイルサーバーに使っていたが
こういう所でも役に立つ。
そして、この際だから一緒に踊る将軍様になった気分で
マツケンサンバIIを踊りましょう!!
叩けボンゴ♪ 響けサンバ♪
閑話休題。
早速、構築してみる事にした。
Sambaの設定については、割愛させていただきます。
詳しくは「システム奮闘記:その34」をご覧ください。
(Sambaでファイルサーバー構築)
さて、まずはクライアント(Windows側)の設定を行う。
Windowsに入れるプリンタードライバーなのだが、
一体、何が該当するのか、わからない。
そこで調べてみると、以下のサイトに情報があった。
http://sourceforge.jp/magazine/07/05/11/0038239/2
HP1200C/PSが良い!
という話だ。
Postscriptプリンターを指定している。
なぜ、Postscriptプリンターなのかは、この時はわからなかった。
理由は後述しています。
早速、Windows側のプリンターの設定を行ってみる。
| プリンター追加のウィザード画面 |
|---|
 |
|
迷う事なく「次へ(N)>」を押す。
|
使用するプリンターがパソコンについている物なのか
それともネットワークプリンターなのかの選択を行う。
| プリンターの種類の選択 |
|---|
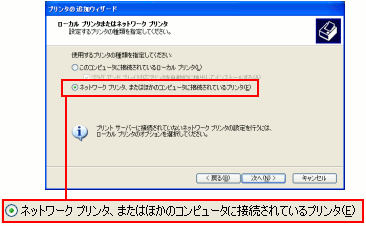 |
パソコンにつながれたプリンターか、ネットワークプリンターかの
選択を行う。今回は、Linuxサーバー上の仮想プリンターなので
赤く囲んだネットワークプリンターを選択する。
|
次に接続先のプリンターの指定を行う。
| 接続先のプリンターの指定 |
|---|
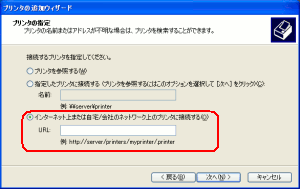 |
Linux上の仮想プリンター接続するのだが
IPPプロトコルを使うため、赤く囲んだ部分に
接続先のプリンターを記述する。
|
接続先のプリンターの記述を行う。
| 接続先のプリンターの記述 |
|---|
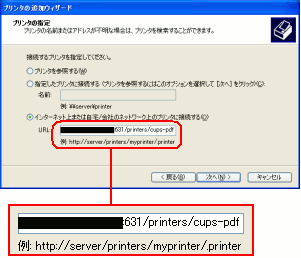 |
プリンターの指定の記述は
http://(プリンターサーバー):631/printers/cups-pdf
なのだ。プリンター名は「cups-pdf」だ。
|
そしてプリンタードライバーの選択だ。
| プリンタードライバーの選択 |
|---|
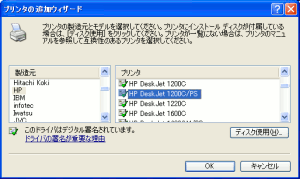 |
プリンタードライバーの選択で、Webサイトに書かれていた
「HP 1200C/PS」を選択する。
この時は気づかなかったのだが、このプリンターは
postscriptプリンターなのだ。なぜ、postscriptなのか
詳細は後述しています。
|
そして通常使うプリンターかどうかの選択だ。
| 通常使うプリンターかどうかの選択 |
|---|
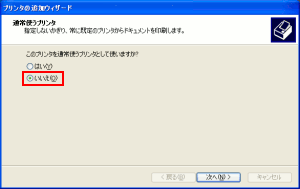 |
実際の印刷のために、他のプリンターを使う事があるので
「いいえ」を選択する。人によっては「はい」が便利かも
|
プリンター設定の完了画面が出てくる。
| プリンター設定完了の画面 |
|---|
 |
|
そのまま「完了」を押す。
|
これでWindows側の設定は完了だ。
Linux側の設定
CUPSの設定は「システム奮闘記:その82」をご覧ください。
(Linuxとcupsでプリンターサーバー構築)
Linux側に仮想プリンターのcups-pdfのドライバのインストールだ。
CUPS-PDFのサイト
cups-pdfのサイト(英語)
RPMでもある。確か、Fodoraのサイトだったと思うのだが
ダウンロードのサイトを記録していなかったので
各人で見つけてください m(--)m
です。
うーん、大事な事は記録する必要があると思う今日この頃。
早速、ダウンロードしたRPM形式のcups-pdfのインストールを行う。
| RPMでcups-pdfのインストール |
|---|
[root@server]# rpm -ihv cups-pdf-2.4.2-2.i386.rpm
準備中... ########################################### [100%]
1:cups-pdf ########################################### [100%]
[root@server]#
|
これでインストール完了。
次に設定ファイルを触るの。
CUPSの設定ファイルを格納している /etc/cupsディレクトリを見る。
(CentOS5.xの場合であって、他のディストリビューションでは違う場合があります)
cups-pdfの設定ファイル、cups-pdf.confがある。
設定ファイルの変更を行う事にする。
| cups-pdf.confの変更 |
|---|
| 変更前 |
### Key: AnonDirName
## ABSOLUTE path for anonymously created PDF files
## if anonymous access is disabled this setting has no effect
### Default: /var/spool/cups-pdf/ANONYMOUS
#AnonDirName /var/spool/cups-pdf/ANONYMOUS
|
| 変更後 |
### Key: AnonDirName
## ABSOLUTE path for anonymously created PDF files
## if anonymous access is disabled this setting has no effect
### Default: /var/spool/cups-pdf/ANONYMOUS
#AnonDirName /var/spool/cups-pdf/ANONYMOUS
AnonDirName /home/samba
|
anonymous接続とは、外部から接続した場合で、
特にサーバーに登録しているIDを使っていない場合での
接続の事を言う。不特定利用者の接続だ。
anonymous接続の場合、生成されるPDFの保管先は
初期設定では「/var/spool/cups-pdf/ANONYMOUS」になる。
それをSambaで公開しているディレクトリ(不特定利用者)が
接続できるディレクトリに変更した。
私の場合「/home/samba」にしましたが、各人の設定によって
変わってきます。
|
PDF変換システム完成!
無事、Linuxとcupsの組み合わせで、PDF変換システムが完成した。
| cups-pdfとSambaを使ったPDF変換の使い方 |
|---|
| 手順(1) |
 |
|
PDF変換したいファイルを開く。
|
| 手順(2) |
 |
|
印刷を選ぶ。
|
| 手順(3) |
 |
|
プリンターを仮想プリンターのcups-pdfを選択する。
|
| 手順(4) |
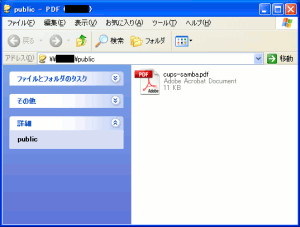 |
CUPSサーバー上で動かしているSambaのフォルダーを見にいく。
するとPDFファイルが生成されているのが、わかる。
|
| PDFファイルを開いてみる |
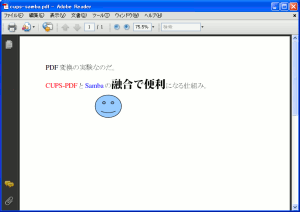 |
|
PDF変換されているのが、一目瞭然だ。
|
早速、よく社内でPDF変換を行う同僚のパソコンに仮想プリンターの
cups-pdfの設定を行い、使い方を説明した。
同僚達が使ってみる。すると・・・
便利やん!!
これは大当たりやん!!
という反応だった (^^)V
これで、めでたし、めでたしで、締めくくりたい所だが
cups-pdfについて、踏み込んで調べる事になった。
cups-pdfの仕組みについて
PDFファイルが簡単に生成できるようになって喜んだのだが
PDFファイルから文字列抽出を行う
OpenOfficeでPDFにした時と違うぞ!
と思った。
OpenOfficeやAcrobatでPDF変換した場合、PDFファイルから
文字列の抽出ができる。
だが、cups-pdfでPDF変換をした場合、文字列の抽出が
ほとんどできない。
一体、この違いは何やねん??
と思った。
そこで調べていく事にした。
ページ記述言語
cups-pdfの仕組みを見ていく際に重要になるのは
ページ記述言語で「システム奮闘記:その82」の
Linuxとcupsでプリンターサーバーで取り上げた。
ページ記述言語の代表例がPostscriptやPDFなのだ。
ここで復習します。
| ページ記述言語 |
|---|
ページ記述言語(PDL:Page Description Language)は
文字や図形を点の集まりで表現せず、描写の記述で表現している。
例えば、円の場合は「中心(X,Y)の座標で半径Zの円」という形で
図形を表現をしている。そのため、画面解像度に依存しない
図形や文字の描写が可能になる。
|
点の集まりで画像を描くのではなく、図形や曲線や色などを
文書で記述して表現している画像の事なのだ。
別名、ベクタ画像ともいう。
文字列についても、点の集まりではなく、
ファイルの中に、文字列データとフォントを組み込んで
それを表示させているのだ。
Linux上からの印刷の場合
ここで仮説を立ててみる事にした。
cupsを動かしているLinux上で、仮想プリンターcups-pdfで
印刷した場合は、生成したPDFファイルから、文字列が抽出できるのかだ。
Linux上から印刷させる場合の仕組みは
以下のようになっている。
| cupsを使ったLinux上での印刷の仕組み |
|---|
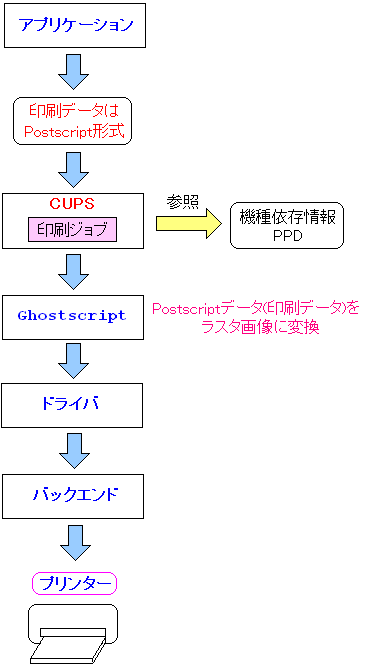 |
アプリケーションは印刷データとしてPostscriptデータを送る。
そして、プリンターは非Postscriptプリンターであっても
postscriptプリンターと見なして、該当のプリンターに合わせた情報を元に
印刷を行えるようにする。
しかし、postscriptデータのままでは非postscriptプリンターでは
印刷不可能なため、ghostscriptでラスター画像に変換する。
ラスター画像は点の集まりの画像。
そのデータをプリンターに送り印刷するという仕掛けだ。
|
cups-pdfという仮想プリンター上で印刷させて
PDF変換を行うのは、以下の仕組みになる。
| cups-pdfの仮想プリンター上でPDF変換の仕組み |
|---|
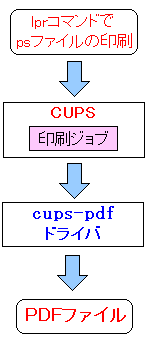 |
Postscriptファイルをlprコマンドで印刷させると
cups-pdfドライバでPDF変換されるという仕組みだ。
PostscriptからPDF変換なので、文字列情報は生きていると考えた。
|
早速、実験を行う事にした。
まずはLinux上で印刷させるための準備として
Postscriptファイルの作成を行った。
といっても、a2psコマンドを使えば簡単にできる。
まずはテキストファイルを作成。
| 作成したテキストファイルの中身(test.txt) |
|---|
[suga@linux]$ more test.txt
This is test file.
[suga@linux]$
|
そしてpostscript変換を行う。
| a2psコマンドでpostscriptファイル作成 |
|---|
[suga@linux]$ a2ps -B test.txt -o test.ps
[test.txt (プレーン): 1ページ, 1シート]
[合計: 1ページ, 1シート] ファイル`test.ps'へ保存します
[suga@linux]$
|
a2psコマンドコマンドのオプションの説明。
「-o」は生成したファイルの指定。
そのため、test.psが生成したpostscriptファイルになる。
「-B」はヘッダーを取り除く。このオプションがないと、
ご丁寧にファイル名の見出しまで付いてくる。
基本的には、1枚の紙に2ページ分を載せる形になる。
|
生成されたpostscriptの中身を見てみる。
| test.psの中身(一部抜粋) |
|---|
%!PS-Adobe-3.0
%%Title: test.txt
%%For:
%%Creator: a2ps version 4.13
%%CreationDate: Sat Nov 14 09:49:12 2009
%%BoundingBox: 24 24 571 818
%%DocumentData: Clean7Bit
%%Orientation: Landscape
%%Pages: 1
(途中、省略)
x0 y0 moveto
(This is test file.) p n
border
grestore
end % of iso1dict
pagesave restore
showpage
%%Trailer
end
%%EOF
|
青い部分が文字列の情報だ。点の集まりの表現ではなく
文字列として生きている事がわかる。
|
早速、仮想プリンター(cups-pdf)でPDF変換を行うため
印刷コマンド(lpr)を実行させてみる。
| lprコマンドで仮想プリンターに印刷 |
|---|
[suga@linux]$ lpr -Pcups-pdf test.ps
[suga@linux]$
|
「-P」オプションはプリンター名の指定。
ここではPDF変換を行うための仮想プリンター(cups-pdf)を指定する。
|
Linux上で仮想プリンターで印刷した場合、生成されたPDFファイルは
/var/spool/cups-pdf/(ユーザ名)のディレクトリに格納される。
| 生成されたPDFファイル |
|---|
[suga@linux]$ pwd
/var/spool/cups-pdf/suga
[suga@linux]$ ls
test.pdf
[suga@linux]$
|
青い部分は生成されたPDFファイルが格納されている場所。
ユーザー名はsugaなので、このディレクトリに格納される。
赤いのが生成されたPDFファイルなのだ。
|
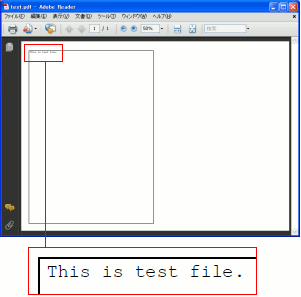
生成されたPDFファイルをAcrobatReaderで開いてみる。
| AcrobatReaderで開いてみた |
|---|
 |
a2psコマンドを使った場合、初期設定では1枚の紙に
2ページ分掲載する形になるため、1ページごとに
大きな枠で囲んで、その中に内容が表示される形になる。
きちんと「This is test file.」が表示されている。
|
PDFファイルの中に、文字列情報が格納されているのか
確かめるために、ファイルの中身を見てみるが・・・
一部、バイナリーでわからへん (--;;
だった。
そこで無償のWindows上で動くソフト「瞬間PDF ZERO」を使う
クロセ 瞬間PDF ZERO
もし、PDFファイルの中に、文字列情報が格納されていたら
文字列を抽出できると考えられるからだ。
早速、試してみる事にした。
| 瞬間PDF ZEROで文字列抽出作業 |
|---|
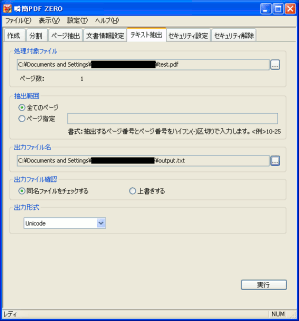 |
テキスト抽出で、対象のファイルと
抽出した物のファイル名を指定を行う。
|
結果は・・・
見事に文字列を抽出できた!
だった。
| メモ帳で抽出結果を見てみる |
|---|
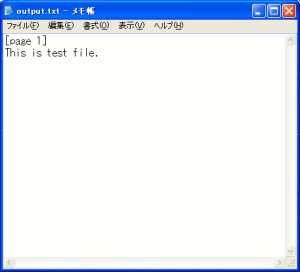 |
PDFファイルの文字列「This is test file.」が
抽出されているのがわかる。
|
どうやらLinux上で作成したpostscriptファイルを
仮想プリンター「cups-pdf」でPDF変換を行っても
文字列情報は生きた状態になっている。
cups-pdfだと文字列が抽出できない場合が多い
さて、Windows側から仮想プリンター(cups-pdf)で
PDF変換させた場合、生成したPDFファイルから文字列の抽出が
うまくいかない事が多い。
| OpenOfficeで文章を書いてみる |
|---|
 |
| 記述した内容 |
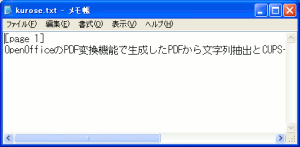
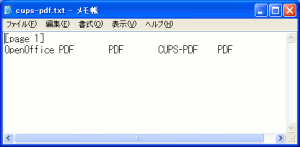
OpenOfficeのPDF変換機能で生成したPDFから文字列抽出と
CUPS-PDFで変換したPDFから文字列抽出を行ってみる。
|
これをOpenOfficeについているPDF変換機能で、PDF変換した場合と
cups-pdfでPDF変換した場合、文字抽出ができるかどうかの
比較をしてみる。
| PDFから文字情報の抽出の比較 |
|---|
| OpenOfficeのPDF変換機能 |
cups-pdfで変換 |
 |
 |
| 文字列の抽出ができた |
ASCII文字だけ抽出ができた。
日本語は駄目だった。 |
そしてOpenOfficeで作った物でも、フォントを変更してみた。
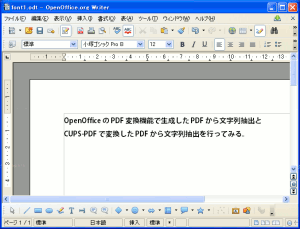
| OpenOfficeで文章を書いてみる |
|---|
 |
| 記述した内容 |
OpenOfficeのPDF変換機能で生成したPDFから文字列抽出と
CUPS-PDFで変換したPDFから文字列抽出を行ってみる。
|
| 作成の状況 |
|
フォントを「小塚ゴシックPro B」を使ってみた。
|
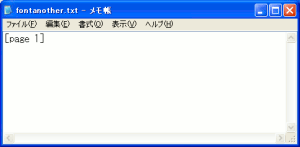
これをcups-pdfでPDF変換を行なった後、生成できたPDFファイルから
文字列抽出を行なってみると・・・
全く文字列が抽出できへん!!
なのだ。
| 文字列抽出の結果 |
|---|
 |
|
文字列が抽出できなかった。
|
つまり・・・
フォントや文字によって抽出できない事がある
日本語の文字列の抽出は壊滅状態なのだ。
一体、Windowsの中でデータが処理されていく過程で
何が起こっているのか。それを知りたくなった。
Windows側(クライアント)からcups-pdfでPDF変換する仕組み
まずは、Windowsからcups-pdfでPDF変換する際の
仕組みから見ていく事にする。
| WindowsからCUPS経由で印刷させる仕組み |
|---|
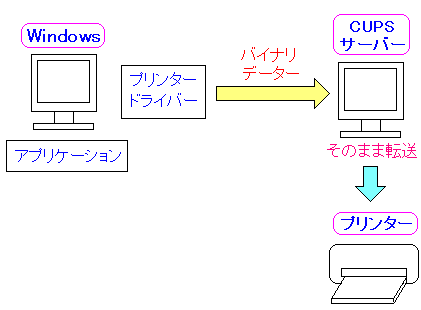 |
Windows側で印刷データをプリンターサーバーへ送り
CUPSは、そのままプリンターへ転送するのだ。
|
ここで思った。
Windows側で何が起こっているのか!
Windows側で印刷データがどうなっているのかを知らないと
謎が解けない事になる。
そこで検索サイトで調べてみる事にした。
すると以下のサイトを発見した。
有限会社きらら21のJustSamba
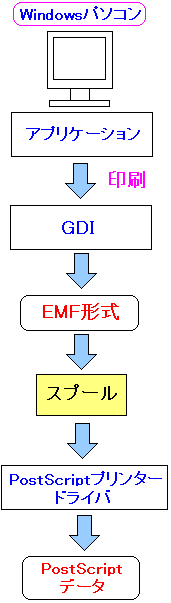
Windows上での印刷の仕組みを図式化すると以下のようになるという。
| Windows上での印刷の仕組み |
|---|
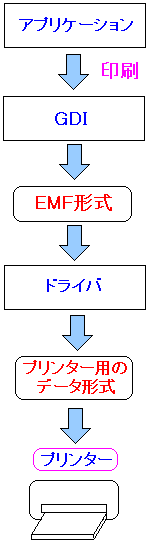 |
(注意)
実は、プリンターの設定を変える事で、GDIを介したEMF形式の
データを作成せずに、直接、アプリケーションからプリンタードライバで
プリンター用のデータを生成する事もあります。
それについては後述しています。
|
これを見て・・・
GDIって何やねん?
EMF形式って何やねん?
なんだか泥沼にハマっていきそうな雰囲気がしてきた。
でも、ここで・・・
事務員だからわかりませーん (^^)
と最強の脱出術(逃げ技)を使っても、何も進まない。
そこで、まずはGDIについて調べてみる事にした。
すると以下の事がわかった。
| GDIとは何か? |
|---|
Graphical Device Interfaceの略
Windowsに搭載されたプログラムの1つ。
プリンターやディスプレーを制御する物。
|
うーん、わかったような、わからんような感じだ。
そう書く事は、つまり、わかっていない事がバレバレ (^^;;
ここで立ち止まって考えても、前に進まないので
GDIは横に置いて、EMF形式について調べてみた。
すると以下の事がわかった。
| EMF形式とは何か? |
|---|
Enhanced Matafile Format(拡張メタファイル)の略
Windowsで印刷を行う時に、高速で印刷を行うために作成される
中間ファイルのファイル形式。
|
これも、わかったような、わからんような感じだ。
つまり、わかっていない事がバレバレ (^^;;
もう少し調べると、印刷データには以下の2種類の
データ形式があるという。
| 印刷データの種類 |
|---|
| EMFデータ |
WindowsのGDI描画コマンドを使って書かれた中間データ形式。
プリンターの機種依存はしない。
|
| RAWデータ |
プリンターが、そのまま解釈できる言語で書かれた印刷データ。
個々のプリンターごとに言語が異なるため、機種依存している。
|
RAWデータ。
ふと思い出した。CUPSの設定を行う際に出てきた。
| WindowsからCUPSサーバーへ印刷させる仕組み |
|---|
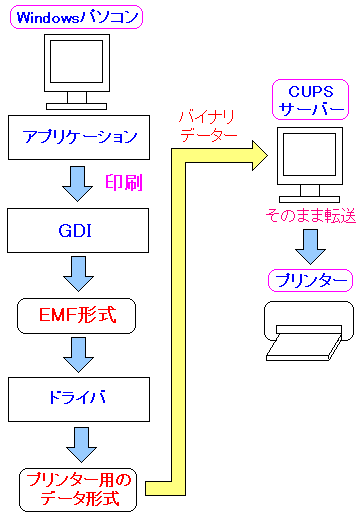 |
Windows側で個々のプリンタに対応した印刷データを作成し
CUPSサーバーにデータを送信し、CUPSは受信した印刷データを
プリンタに転送し、印刷させる仕組みだ。
|
初期設定では、RAWデータの受付拒否しているため
それを解除するため、2つの設定ファイルの記述変更を
必要があった。
| /etc/cups/mime.convsファイル |
|---|
| 変更前 |
########################################################################
#
# Raw filter...
#
# Uncomment the following filter to allow printing of arbitrary files
# without the -oraw option.
#
#application/octet-stream application/vnd.cups-raw 0 -
|
| 変更後 |
########################################################################
#
# Raw filter...
#
# Uncomment the following filter to allow printing of arbitrary files
# without the -oraw option.
#
application/octet-stream application/vnd.cups-raw 0 -
|
|
コメントの「#」を外し、この部分を有効にした。
|
そして、もう1つの設定ファイルの記述も変更する必要があった。
| /etc/cups/mime.typesファイル |
|---|
| 変更前 |
########################################################################
#
# Raw print file support...
#
# Comment the following type to prevent raw file printing.
#
#application/octet-stream
|
| 変更後 |
########################################################################
#
# Raw print file support...
#
# Comment the following type to prevent raw file printing.
#
application/octet-stream
|
|
ここでも、コメントの「#」を外し、有効にした。
|
Windowsで生成されたプリンターが理解できる言語形式の
印刷データを、CUPSが受信して、プリンターに転送するのを
可能にするための設定だ。
ちなみに、今までRAWデータの事を
生データ!!
と思っていた。まさに直訳だ。
もちろん、印刷するための生のデータなので間違いないが
もっとわかりやすい表現にすると、プリンターが理解できる言語の
データ形式になったデータというのだ。
仮想プリンター(cups-pdf)で、PDF変換を行う際
Windows側からRAWデータを加工しているのだろうか?
でも、バイナリーのRAWデータをページ記述言語の
PDFに書き換える事が簡単にできるのだろうか?
cups-pdfのソースコードを眺めてみても・・・
PDFに変換する部分が見当たらへん・・・
もしかして、他のコマンドと連動しているのではないか?
そもそもRAWデータをPDF変換していないのでは・・・
そこでCUPS側でRAWデータの転送を拒否するような設定にする事にした。
つまり、CUPSの初期設定に戻すのだ。
| /etc/cups/mime.convsファイル |
|---|
| 初期設定に戻す |
########################################################################
#
# Raw filter...
#
# Uncomment the following filter to allow printing of arbitrary files
# without the -oraw option.
#
#application/octet-stream application/vnd.cups-raw 0 -
|
| /etc/cups/mime.typesファイル |
|---|
| 初期設定に戻す |
########################################################################
#
# Raw print file support...
#
# Comment the following type to prevent raw file printing.
#
#application/octet-stream
|
すると・・・
それでもPDF変換される!
これでRAWデータをcups-pdfがPDF変換している事は
ありえないと断定できた。
一体、どうなっているのか。
手っ取り早い方法として、cups-pdfでPDF変換される前の段階で
Linux側のスプールに保管される印刷データを見てみる事にした。
cups-pdfを停止させて、スプールのディレクトリを見てみる。
| Linux側のスプール(var/spool/cups) |
|---|
[root@linux]# ls
d00425-001 tmp
[root@linux]#
|
赤い部分がWindows側でcups-pdfで印刷処理した際に
Linux側に送られる印刷データのファイルだ。
|
早速、ファイルの中身を見てみる事にした。
| d00425-001の中身 |
|---|
[root@linux]# more d00425-001
%-12345X@PJL JOB
@PJL ENTER LANGUAGE=POSTSCRIPT
%!PS-Adobe-3.0
%%Title: <836583588367>
%%Creator: PScript5.dll Version 5.2.2
%%CreationDate: 11/13/2009 14:49:36
%%For: XXXXX
%%BoundingBox: (atend)
%%Pages: (atend)
%%Orientation: Portrait
%%PageOrder: Special
%%DocumentNeededResources: (atend)
%%DocumentSuppliedResources: (atend)
%%DocumentData: Clean7Bit
%%TargetDevice: (HP DeskJet 1200C) (2014.102) 1
%%LanguageLevel: 2
%%EndComments
(以下省略)
|
|
中身はPostscriptファイルだった。
|
つまり、Windowsから直接・・・
Postscriptデータが送信されとるんか!
RAWデータではないため、たとえ、CUPSの設定で
RAWデータの受付拒否しても、問題なく使えるのだ。
それにしても謎が出てきた。
Windows側でpostscriptデータを生成する形になっている。
別にWindows側でPostscript生成の設定をしているわけでもない。
なんでやねん!!
だが、ふと思った。
cups-pdfに使っている
プリンターのドライバ名に着目した!
そう、プリンターのドライバを入れる部分をおさらいしてみると
| プリンタードライバーの選択 |
|---|
|
プリンタードライバーの選択する際、「HP 1200C/PS」を
選択していた。
後ろの「PS」に着目した。
もしかして「PostScript」の略ではないだろうか
|
Postscriptプリンターのドライバを使っているから
ドライバーがPostscriptデータを生成している!
と思った。
そこで、仮想プリンターのcups-pdfをWindowsに入れる際、
非Postscriptプリンターのドライバーをいれてみる事にした。
| エプソンのPM-870Cを選ぶ |
|---|
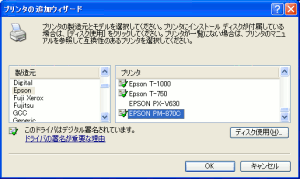 |
cups-pdfの仮想プリンター用のドライバとして
エプソンのPM-870Cを選んでみた。
|
これでPDF変換を行ってみると・・・
中身が空っぽのPDFファイルやん!!
つまりPDF変換できていないのだ。
いくつかの非Postscriptプリンターのドライバや
Postscriptプリンターのドライバを使って実験を行ってみた。
すると以下の結果になった。
| 実験結果 |
|---|
| (1) |
非postscriptプリンターのドライバを使用した場合
全くPDF変換ができなかった。
中身が空っぽのPDFファイルしか生成されない。
|
| (2) |
postscriptプリンターのドライバを使用した場合
無事、PDF変換ができた。
|
結論が出た。
Windows上で、仮想プリンターのcups-pdfの
ドライバを設定する際は
Postscriptプリンターのドライバーを使うべし!
なのだ。
そしてサイトに書いてあった、最適なドライバ(HP 1200C/PS)は
PDF変換の際、もっともA4の大きさに当てはまるドライバだと思われる。
Windows内でpostscriptデータが生成されるという事なので
以下の仕組みになっていると思った。
ここまで、仮想プリンターのcups-pdfを使ったPDF変換の仕組みは
以下の通りだ。
| cups-pdfでPDF変換の仕組み |
|---|
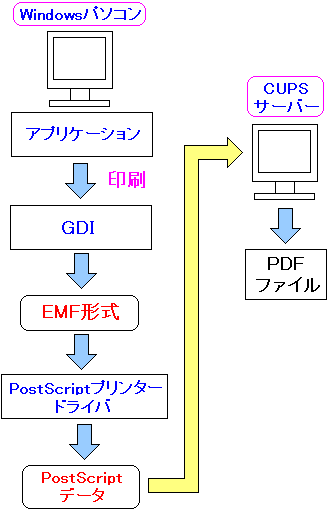 |
Windows側でアプリケーションが印刷を行うと
GDIを介してEMF形式のデータが生成される。
その後、PostScriptプリンタードライバによって
Postscript形式の印刷データに変換されて、
CUPSサーバーに印刷データが送られる。
そしてPDFファイルに変換される。
|
ところで、CUPSサーバー側で受け取ったPostscriptデータは
どうやってPDFファイルに変換されるのか。
cups-pdfのソースを読んだり、設定ファイルを見ると
仕組みがわかるのだ。
| cups-pdf.cのソース抜粋(Ver2.5.0) |
|---|
(途中、省略)
int main(int argc, char *argv[]) {
char *user, *dirname, *spoolfile, *outfile, *gscall, *ppcall;
cp_string title=&qupt;";
(途中、省略)
(void) umask(0077);
size=system(gscall);
snprintf(title,BUFSIZE,"%d",size);
(以下、省略)
|
青い部分はcups-pdfが実行するコマンドを格納するための部分。
赤い部分は、外部コマンドを実行するsystem()だ。
|
どのコマンドを実行させるのか。
その正体は、ヘッダーファイルの中に隠されている。
| cups-pdf.hの中身を抜粋(Ver2.5.0) |
|---|
(途中、省略)
snprintf(conf.ghostscript,BUFSIZE,"/usr/bin/gs");
snprintf(conf.gscall,BUFSIZE,"%s","%s -q -dCompatibilityLevel=%s -dNOPAUSE -dBATCH -dSAFER -sDEVICE=pdfwrite -sOutputFile=\"%s\" -dAutoRotatePages=/PageByPage -dAutoFilterColorImages=false -dColorImageFilter=/FlateEncode -dPDFSETTINGS=/prepress -c .setpdfwrite -f %s");
(以下、省略)
|
青い部分が実行するコマンド。gs(ghostscript)なのだ。
赤い部分はオプションの一部で、PDF変換の指定が行なわれている。
|
ここでわかった事は、cups-pdfの役目は
gsコマンドの実行なのらー!!
特に、cups-pdf内部で、PDF化の処理を行なうような実装は
されていないのだ。
これでPostscriptデータからPDFに変換しているのだ。
cups-pdfの概略を図にすると以下のようになる。
| cups-pdfの概略 |
|---|
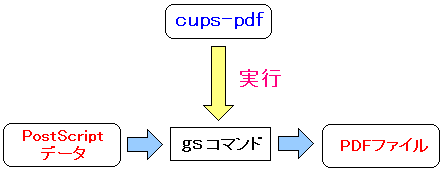 |
cups-pdfのソースの一部しか読んでいないが、system()を使って
gsコマンドを呼び出して、PDFに変換している事がわかった (^^)
Windows側の印刷の仕組みについて
Windows側で印刷データをGDIを使ったEMF形式にし
その後、PostScriptプリンタードライバによって
PostScript形式に変換している事はわかった。
でも、ここでわからない事が残っている。
EMF形式って、どんな形式のデータやねん?
踏み込んでいかないと、cups-pdfでPDF変換を行った場合
文字列抽出ができなくなる事がある理由を知るための
手がかりが見えてこないのだ。
でも、言葉だけでは、わかったような、わからんような感じだ。
そこで思った。実際に
EMF形式のデータを取り出してみたら、ええかも!
だが、すぐに壁にぶち当たる。
どうやってEMF形式のデータを取り出すねん!
うーん、どの段階でEMF形式のデータが作成され、
そして、どの段階でPostScriptに変換されるのか、わからない。
ふと、次の事に気づいた。
Windowsには印刷スプールがあるのか?
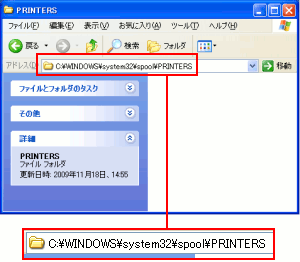
調べてみると、Windowsにも印刷スプールがある事を知る。
WindowsXPの場合、以下のフォルダーがスプールなのだ。
| WindowsXPのスプールフォルダー |
|---|
 |
|
スプールのフォルダーはシステム領域に存在する。
|
早速、スプールに溜ったデータを見てみようと思った。
ところでスプールに溜るデータは・・・
どんな形式やねん?
Postscriptプリンターの場合、2つのうち、どちらかが
考えられる。
| スプールに溜るデータ形式はどっち? |
|---|
| Postscript形式 |
EMF形式 |
 |
 |
どっちの仕組みになっているのか。
この時、調べてみたのだが、仕組みを説明した物が見つからなかった。
|
そこで思った。
実際に、目で確かめて見ればエエやん!
スプールに保管された印刷データを見るのだが、
印刷データの取り出しを行いやすくするため、Postscriptプリンターを
Windowsパソコン本体へのローカル接続の設定を行う事にした。
実際には、Postscriptプリンターはないため、設定のみですが。
Postscriptプリンターの設定
さて、Postscriptプリンターの設定を行う事にした。
| プリンターの接続設定 |
|---|
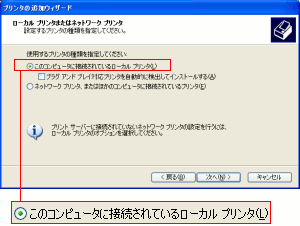 |
ローカル接続を行うため、赤く囲んだ部分を選択します。
そして「次へ(N)」を押します。
|
次に、ローカル接続の形態を選択画面。
| ローカル接続の形態の選択画面 |
|---|
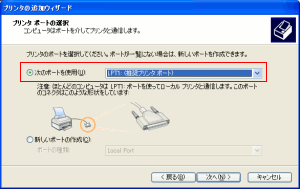 |
ここは迷う事なく、初期設定の物を選ぶ。
スプールに溜めるだけで、実際に出力しないからだ。
|
| プリンタードライバーの選択 |
|---|
|
プリンタードライバーの選択で「HP 1200C/PS」を選択する。
CUPS-PDFに適したPostscriptプリンターだが
Windowsのスプールに溜る印刷データがEMF形式なのか
Postscriptデータなのかを見るためだけなので
Postscriptプリンターのドライバーなら何でも良いです。
|
そして通常使うプリンターかどうかの選択だ。
| 通常使うプリンターかどうかの選択 |
|---|
|
|
実際に印刷には使わないので「いいえ」を選択する。
|
プリンター設定の完了画面が出てきたら、設定完了だ。
これで準備完了。
スプールに溜ったデータの取り出し
さて、Windows上で印刷させると、印刷データはスプールに溜る。
(プリンタの設定で、スプールの溜らない場合もありますが後述しています)
早速、設定したプリンタを使って
| プリンターの一覧 |
|---|
 |
赤く囲んだのは設定したプリンターです。
ローカル接続のPostscriptプリンターですが
実際にはプリンター本体はつながっていません。
|
そしてスプールに溜るように、プリンターを一時停止させます。
| プリンターの一時停止のための手順 |
|---|
| 一時停止前 |
 |
| 作業中 |
 |
| 一時停止 |
 |
そこで実際に印刷をしてみる。
| 印刷データを作成する |
|---|
|
|
スプールに印刷データを溜めるため印刷作業を行なう。
|
印刷したあと、プリンターの様子を見てみる。
| プリンターの印刷ジョブ |
|---|
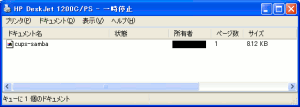 |
|
印刷データが溜っている事がわかる。
|
印刷データが溜っているスプールのフォルダーを見てみる。
| スプールのフォルダー |
|---|
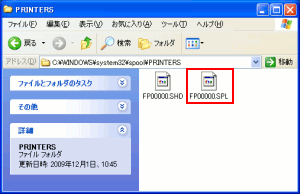 |
印刷データがあるのがわかる。
赤く囲んだ、拡張子がSPLのファイルが印刷データだ。
|
赤く囲んだファイルのデータ形式。
EMF形式なのか、それともプリンターが解釈できるデータ形式
(この場合、Postscript形式)なのか。
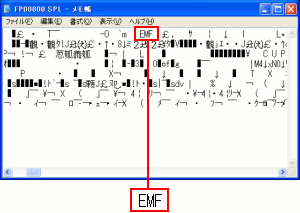
メモ帳を使って見てみる事にした。
| 印刷データをメモ帳で開いてみる |
|---|
 |
|
EMFという記述があったので、どうやらデータはEMF形式だ。
|
よって、ここで判明したのは
Windowsのスプール上のデータは
EMF形式なのだ!
スプールの後で、各プリンターのドライバによって
それぞれのプリンターが解釈できるファイル形式に変換される。
早速、EMF形式のデータを見てみた。
WindowsビューアでEMF形式は開く事ができるようなので、
ファイルの拡張子を「SPL」から「EMF」に変更してみた。
| 拡張子をEMFに変更 |
|---|
 |
|
EMFという拡張子が、画像を開くソフトと関連づけできる様子がわかる。
|
そこでファイルをクリックしてみる。
だが・・・
なんで開かへんねん!!
だった。
| 画像が開かない様子 |
|---|
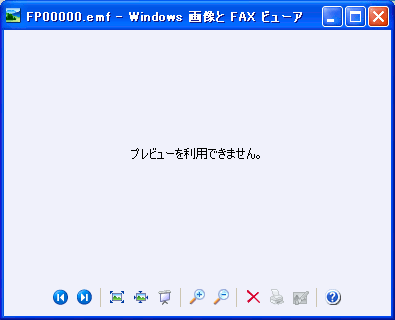 |
Windowsの印刷スプールに溜っていた印刷データを
読み込んだのだが開く事ができなかった。
|
そこで、開かない原因を調べてみる事にした。
するとマイクロソフトのサポートのサイトで解説があった。
http://support.microsoft.com/kb/436043/ja
印刷データの原型になるEMFは「NT EMF」形式という物だ。
サイトを読むと・・・
NT EMF形式は仕様が非公開なのらー!!
仕様非公開という特殊なEMF形式なのだ。
特殊な関数によって開く事ができるデータなのだ。
ここで終わったと思いながらも、EMF形式に関して調べていくと
思わぬサイトを発見した。
DEKOのじゅんくぼくす
ここで公開しておられるスプールファイル変換ツールのsplconvが
Windowsのスプールにある印刷データ(NT EMF)を、簡単に開く事ができる
EMF形式に変換してくれるのだ。
早速、ダウンロードして使ってみる事にした。
| splconvを使ってみる |
|---|
 |
splconvを起動させた。
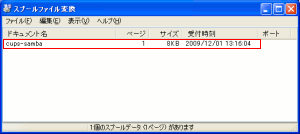
| splconvを起動 |
|---|
 |
|
スプ−ルに溜っている印刷データが表示されている。
|
そしてメタファイル(EMF形式)として保管する。
| EMF形式として保管 |
|---|
 |
| ファイル名の指定 |
 |
スプールにあった印刷データ(NT EMF)を、容易に見れるEMF形式に
変換する事ができた。
| EMF変換終了 |
|---|
 |
|
EMF形式に変換されたデータが落し込まれている。
|
早速、落し込まれたEMFデータのファイルをクリックする。
すると・・・
見事に、開く事ができたのら-!! (^^)V
| Windowsビューアで開いた様子 |
|---|
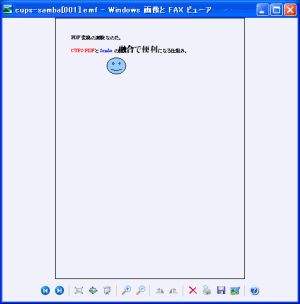 |
これで実験的に
スプールにはNT EMF形式のデータが溜る!
事がわかったのだ。
なので印刷の過程の図式は、以下のようになっている事がわかった。
印刷の過程とデータ変換の流れ
(Postscriptプリンターの場合) |
|---|
|
この実験の後、マイクロソフトのサイトを発見した。
印刷時のスプリングについて
Windowsで印刷する際の印刷過程が載っていた。
これを先に知っておけば実験せずに済んだのにと思いながらも
多分、「目で確認しないと納得できん」で実験はやっていたと思う (^^)
ちなみに、EMF形式のデータを作成せずに、アプリケーションから
直接、各プリンターに適応した印刷データを送る事もできる。
| プリンターのプロパティー(詳細設定) |
|---|
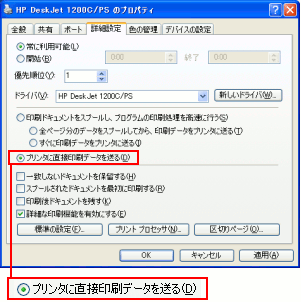 |
|
赤く囲んだ部分を選択する。
|
すると、以下の仕組みでEMF形式のデータをスプールに溜めずに
直接、プリンターに印刷データを送る事ができる。
印刷の過程とデータ変換の流れ
(Postscriptプリンターの場合) |
|---|
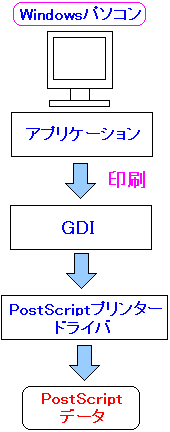 |
スプールにEMFデータを溜めずに、直接、プリンターに印刷データを
送り込む仕掛けになる。
この方式の問題点としては、アプリケーションがプリンターに
印刷データ送信し終えるまで、他の作業ができなくなる事だ。
EMFの場合、軽量で変換しやすいため、アプリケーションが
簡単にEMF形式の印刷データを吐き出し、次の作業に移行できる。
ただ、昔の話で、今のようにCPUなどが高速化していると
数ページ程度の印刷では、全く変わらないのだ。
|
もちろん、こんな機能を知ったのは
今回が初めてなのらー (^^)
という事で、プリンターの設定に関して、少し賢くなったのだった。
どこで文字列が消失するのか?
OpenOfficeで文章を作成し、cups-pdfを使って
PDF変換を行なう際、どの辺りで、文字列が消失するのか。
印刷データのEMF形式が生成された時なのか?
それともPostscriptに変換された時なのか?
ここは自分の目で確かめようと思った。
EMF形式のデータなのだが
PDFやPostscriptと同様にページ記述言語なのだ
早速、2つの異なるフォントを織りまぜた文章を作成してみた。
| 2つのフォントを織りまぜて文章作成 |
|---|
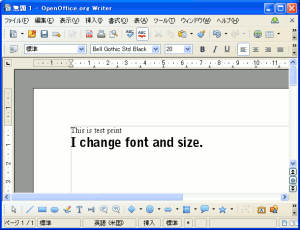 |
| 文書の内容 |
This is test print.
I change font and size.
|
| フォントなどについて |
|
2種類のフォントと文字の大きさを使った文字列を作成しました。
|
これを印刷する事にします。
印刷データでスプールに溜った状態のNT EMF形式から
splconvを使って、EMF形式に変換。
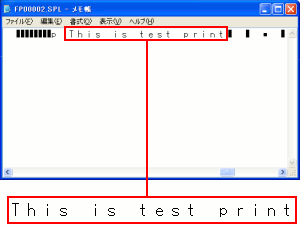
そしてメモ帳でEMFのデータを開いてみる事にした。
| メモ帳面で開いてみた |
|---|
 |
|
フォントの情報が記述されている。
|
 |
|
文字列情報が活用されているのがわかる。
|
もう1つの文字列を見てみる。
こちらも文字列が生きている。
| メモ帳で開いてみた |
|---|
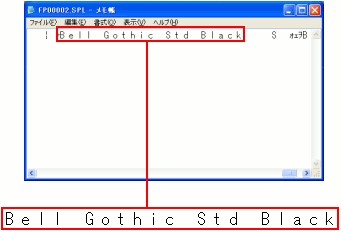 |
|
フォントの情報が記述されている。
|
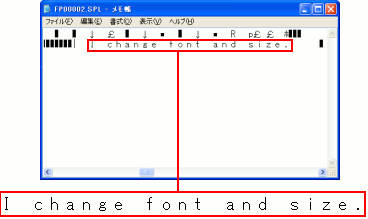 |
|
文字列情報も記述されている。
|
つまり・・・
EMFの段階では文字情報は生きているのだ!
だった。
そして、Postscriptプリンターのドライバによってデータが
Postscript形式に変換された後、データの中身を見てみた。
| Postscriptデータの中身を見てみる |
|---|
%-12345X@PJL JOB
@PJL ENTER LANGUAGE=POSTSCRIPT
%!PS-Adobe-3.0
%%Title: <96B391E831>
(途中、省略)
/Euro /Times-Roman /Times-Roman-Copy BuildNewFont
} if
F /F0 0 /256 T /Times-Roman mF
/F0S32 F0 [50 0 0 -50 0 0 ] mFS
F0S32 Ji
179 233 M (This is test print.)[31 25 13 20 12 13 20 13 14 22 19 14 13 25 17 13 24 15 0]xS
27000 VM?
(以下、省略)
|
青い部分が文字列の情報だ。
EMF形式からpostscriptへ変換の際、問題なく受け継がれている。
|
だが、もう1つのフォントで作った文字列情報は
全く見つからへんやん!!
だった。
Postscriptに含まれていないフォント、Postscriptプリンターに
登録されていないフォントの可能性がある。
その場合、どうやって文字列のデータを、どう扱うのか。
以下の仮説を立ててみた。
| 仮説 |
|---|
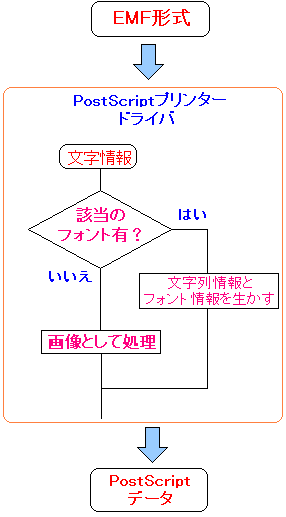 |
対応できるフォントがある場合は、そのまま引き継ぎ
そうでない場合は、画像として加工処理を行なう。
|
果して、この仮説が正しいかどうかなのだが・・・
いくら調べても、わかりませーん (^^;;
だった。
さすがに調べるのも大変なので、一端、ここで断念する事にした。
事務員の私。技術者でないため、ここで力尽きてしまった・・・。
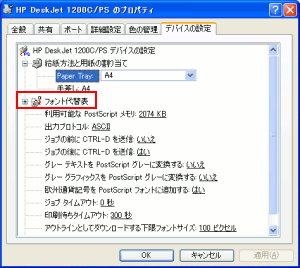
ところで、Postscriptプリンターのプロパティーを見てみると
該当フォントがない場合の処理の選択がある。
| フォントの代替の設定(デバイスの設定) |
|---|
 |
|
赤く囲んだ「フォントの代替表」を選ぶ。
|
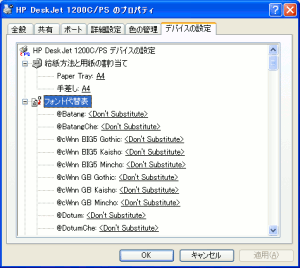 |
各フォント事に、代替するフォントを選択できる。
該当するフォントがない場合、どのフォントを代替するかの選択だ。
|
これを見る限り、文字列情報を画像データに変換しているのではなく
16進数表現の文字列として生きているかもしれない。
そのため、文字列の抽出ができていない可能性も考えられる。
でも、あくまでも推測の域を越えない。
結論としては・・・
EMFからPostscriptへ変換時に影響されている
という事だけは言えると思う。
と結論づけたい所だったが・・・
危うく大ウソ書く所だった (^^;;
もう一度、どの印刷物かを確認してみる。
| 2つのフォントを織りまぜてOpenOfficeで文章作成 |
|---|
|
| 文書の内容 |
This is test print.
I change font and size.
|
| フォントなどについて |
|
2種類のフォントと文字の大きさを使った文字列を作成しました。
|
これを仮想プリンターのcups-pdfで印刷(PDF変換)を行なう。
| PDF変換されたもの |
|---|
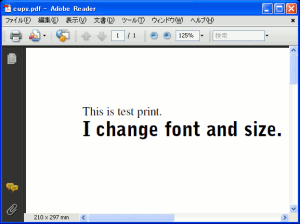 |
これから文字列を抽出すると・・・
無事、抽出できたのらー!!
| 抽出した様子 |
|---|
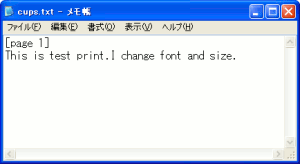 |
どうやら半角英数は問題なく抽出できる感じだ。
でも、Postscriptのデータには2行目の部分である
「I change font and size.」を見なかった。
そこで、もう一度、PDF変換前のPostscriptデータを見てみる事にした。
| Postscriptデータの中身を見てみる |
|---|
%-12345X@PJL JOB
@PJL ENTER LANGUAGE=POSTSCRIPT
%!PS-Adobe-3.0
%%Title: <96B391E831>
(途中、省略)
/Euro /Times-Roman /Times-Roman-Copy BuildNewFont
} if
F /F0 0 /256 T /Times-Roman mF
/F0S32 F0 [50 0 0 -50 0 0 ] mFS
F0S32 Ji
179 233 M (This is test print.)[31 25 13 20 12 13 20 13 14 22 19 14 13 25 17 13 24 15 0]xS
27000 VM?
(途中、省略)
F /F1 0 /0 F /ADCFAA+BellGothicStd-Black mF
/F1S53 F1 [83 0 0 -83 0 0 ] mFS
F1S53 Ji
179 322 M <010203040506070802090A060B0205060C020D0E0F0810>[32 23 42 46 42 46 46
42 23 29 46 46 33 23 42 46 46 23 37 23 37 42 0]xS
LH
(以下、省略)
|
青い部分が文字列の情報だ。
この部分は、誰でもわかる文字列になっている。
そして赤い部分が2行目の「I change font and size.」の部分のようだ。
16進数になっているらしく、見落としていた (^^;;
|
でも、2行目も文字として抽出できるのかどうか、別の方法で確認してみた。
ps2asciiコマンドを使ってみた。
| ps2asciiコマンドを使ってみた |
|---|
[suga@linux]$ ps2ascii d01221-001.ps d01221-001.txt
[suga@linux]$ more d01221-001.txt
%%[ ProductName: ESP Ghostscript ]%%
This is test print.I change font and size.^L%%[Page: 1]%%
%%[LastPage]%%
[suga@linux]$
|
1行目の文字列の抽出結果は青色。
2行目の文字列の抽出結果は赤色。
半角英数はフォントの関係でPostscriptデータでは
16進数(?)になっていても、問題なく復元できるようだ。
|
この事から、Windows内部でEMFからPostscriptに変換する際には
全く影響されないようだ。
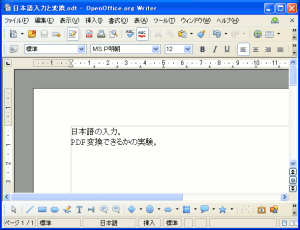
さて、次に日本語の文章をPDF変換した時を見てみた。
| OpenOfficeで日本語の文章作成 |
|---|
 |
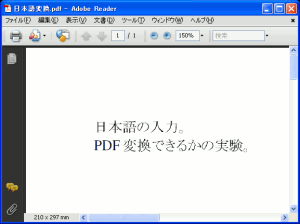
これを仮想プリンター・cups-pdfでPDF変換を行なってみる。
| PDF変換した結果 |
|---|
 |
このPDFファイルの文字列抽出を行なってみた。
| 文字列抽出を行なった結果 |
|---|
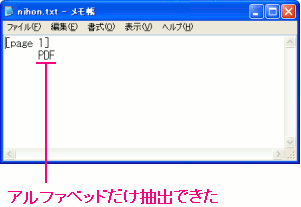 |
「PDF」というアルファベッドだけが抽出できた。
この部分は半角英数で記入したので、抽出できたと思う。
|
日本語文章をPDF変換する過程での、Postscriptデータの状態で
中身を見てみる事にした。
| Postscriptデータの中身 |
|---|
%-12345X@PJL JOB
@PJL ENTER LANGUAGE=POSTSCRIPT
%!PS-Adobe-3.0
%%Title: <93FA967B8CEA93FC97CD82C695CF8AB7>
(途中、省略)
/F1S32 F1 [50 0 0 -50 0 0 ] mFS
F1S32 Ji
179 309 M (PDF)[28 36 0]xS
996 VM?
(途中、省略)
F0S32 Ji
281 309 M <0809>[50 0]xS
1994 VM?
(以下、省略)
|
赤い部分は、半角英数の部分の「PDF」の文字列だ。
青い部分は「変換」の部分と思われる。日本語なので16進数に
変換されていると思われる。
|
この時点で、日本語の文字列が抽出可能かどうか
確かめたかったのだが、ps2asciiコマンドでは
日本語は抽出できないので、断念した。
さて、上の青い部分を次のように置き換えた。
| Postscriptデータの中身 |
|---|
%-12345X@PJL JOB
@PJL ENTER LANGUAGE=POSTSCRIPT
%!PS-Adobe-3.0
%%Title: <93FA967B8CEA93FC97CD82C695CF8AB7>
(途中、省略)
/F1S32 F1 [50 0 0 -50 0 0 ] mFS
F1S32 Ji
179 309 M (PDF)[28 36 0]xS
996 VM?
(途中、省略)
F0S32 Ji
281 309 M <AB23>[50 0]xS
1994 VM?
(以下、省略)
|
青い部分を「0809」から「AB23」に書き換えた。
特に「AB23」には意味はありません。
|
Postscriptデータを書き換えた後、gimpで開いてみると
歯抜けになっているのだ!!
だった。
| gimpで開いた結果 |
|---|
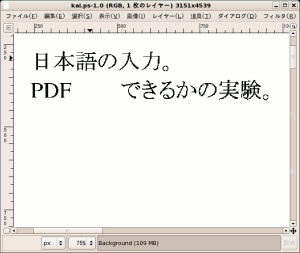 |
|
「変換」の部分が歯抜けになっている。
|
この事から、日本語が消失するのは、ghostscriptで
PDFに変換される時ではないかと思ったりする。
でも、証拠がないだけに
わかりませーん(^^)
としたいと思います。
まとめ
CUPSでプリンターサーバーを構築ができ、すぐ後で仮想プリンターの
cups-pdfを使って、PDF変換ができる事を知りました。
これを使うと、無料でPDF変換ができるため、非常に便利です。
Acrobatの場合、有償な上、CADなどのソフトでは使えないため
印刷機能が使えるソフト全般に対応できる仮想プリンターは便利です。
その反面、変換したPDFファイルからの文字情報を
抽出できない場合も多く、Acrobatを使って、文字の訂正や修正が
できない問題点もあります。
次章:「IT予算管理入門」を読む
前章:「LinuxとCUPSでプリンターサーバー構築」を読む
目次:システム奮闘記に戻る